+7 (495) 291-32-04
Key Collector + конструктор UTA-manager. Практический мануал по быстрой настройке Яндекс.Директ
Это практическое пособие с примерами того, как научиться быстро настраивать рекламные кампании в Яндекс.Директ с помощью UTA-manager.
В результате:
- Сокращение трудозатрат на очистку семантического ядра от мусора и минусов примерно в 2-3 раза по сравнению с ручным режимом или использованием Excel.
- За счет сбора расширенной статистики частотностей снижается вероятность получить статус "мало показов".
- Полуавтоматическая кластеризация запросов позволит создать максимально релевантные группы объявлений.
- Контролируемое полуавтоматическое создание рекламных объявлений для Яндекс.Директ и Google Ads.
- Опираясь на статистику, система подберет оптимальный ключевой запрос для подстановки в заголовок.
- На выходе система подготовит CSV-файл для выгрузки рекламной кампании в Яндекс или Google.
Задача:
- Настроить рекламную кампанию в поисковой системе Яндекс для интернет-магазина.
- Тематика: продажа электрических чайников.
- Провести тестирование по заданным условиям, сделать выводы.
Условия:
Разделить трафик на несколько сегментов и оценить эффективность каждого.
Сегменты должны быть следующие:
- Общий неуточненный спрос:
-
запросы типа «Купить электрочайник» «Электрочайник +характеристика/свойство».
-
- Общий неуточненный спрос с ГЕО-добавками:
-
запросы типа «Купить электрочайник +В Москве».
-
- Уточненный спрос, товары, имеющиеся в наличии:
-
запросы типа «Электрочайник +марка/модель».
-
- Уточненный спрос по товарам, которых нет в наличии, но они есть у конкурентов:
-
запросы типа «Электрочайник +марка/модель».
-
Порядок выполнения работ:
- Знакомство с проектом
- Сбор семантического ядра
- Очистка ядра от мусора
- Составление списков минус-слов
- Группировка ключевых слов по смыслу и по условиям
- Создание релевантных объявлений для каждой группы
- Выгрузка кампании в Яндекс.Директ
Используемые инструменты:
- Key Collector для сбора ключевых фраз (можно использовать и другие сервисы для парсинга ключевых фраз);
- сервис Wordstat для сбора базовых запросов;
- расширение для браузера WordStater (установка здесь https://goo.gl/Pme8i5);
- сервис UTA-manager для быстрой очистки ядра, группировки и составления релевантных объявлений (регистрация https://uta-manager.ru);
- Excel и светлая голова.
Подготовка
На этапе подготовки знакомимся с проектом.
Определяем спрос, товары/марки, имеющиеся в наличии, выписываем характеристики и свойства товаров, имеющихся в наличии.
С помощью сервиса Wordstat и плагина “WordStater” анализируем спрос и составляем предварительную карту запросов.
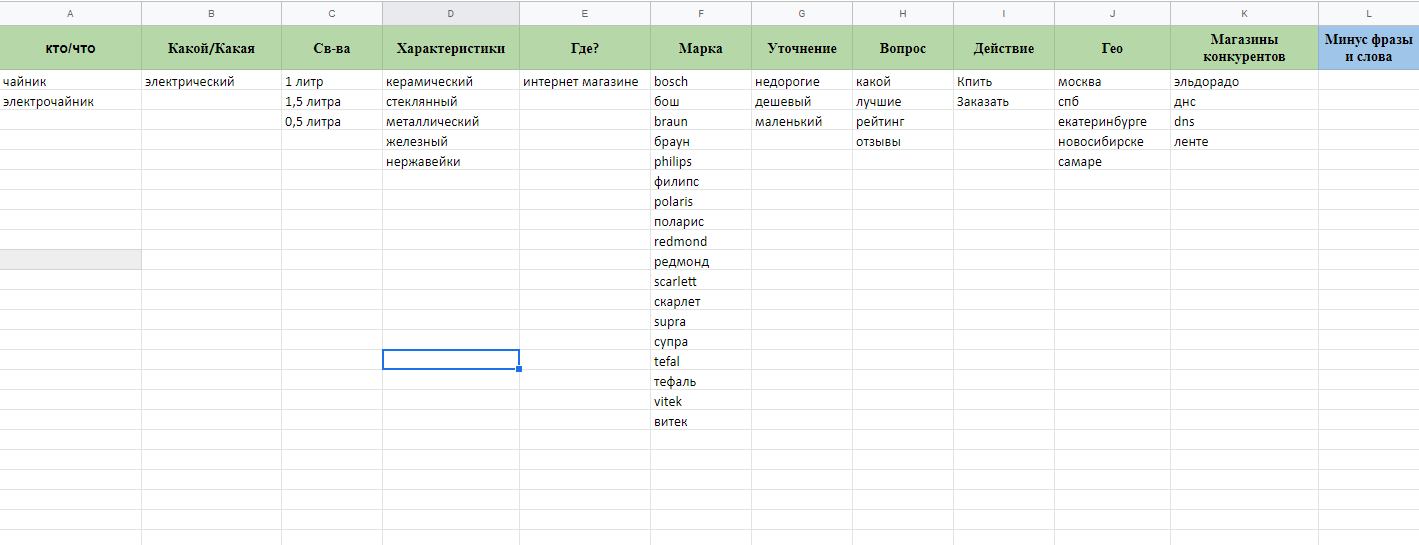
Карта поможет понять, что и как ищет целевая аудитория. Также она позволяет грамотно структурировать рекламную кампанию, определить группы, посадочные страницы, зафиксировать товары в наличии и так далее.
Другими словами, карта спроса является основой для построения логики рекламной кампании.
Важный момент! Карта запросов помогает понять состав поисковых запросов и выявить важные нюансы спроса, что в дальнейшем очень упрощает настройку.
Альтернативный способ составления семантического ядра
Есть ряд специалистов, которые при запуске тестовых рекламных кампаний не собирают ключевые запросы. Семантическое ядро генерируется путем перемножения слов из карты.
На этот счет ведется много споров, но, в любом случае, каждый специалист волен поступать как ему удобно, главное - чтобы цель была достигнута.
Если вы предпочитаете генерацию ключевых запросов, то в этом случае важно очистить получившийся список от бессмысленных фраз и запросов, не имеющих частотности.
Очистка сгенерированного ядра производится за счет счет сбора статистики частностей по каждому из получившихся вариантов, при этом важно собрать статистику с учетом дополнительных операторов WordStat, чтобы определить порядок слов во фразе, правильные словоформы и т.д.
В итоге запросы, имеющие частотность и смысл, остаются, а нулевые удаляются.
По ссылке вы найдете видеоурок по тому, как сгенерировать семантическое ядро, также рекомендую ознакомиться с уроком по быстрому сбору статистики.
Сбор семантического ядра с помощью Key Collector
После знакомства с проектом, изучения спроса и составления карты запросов в фоновом режиме запускаем Key Collector, он поможет собрать все ключевые запросы в тематике.
В нашем случае сбор будет идти по определениям из карты запросов.
В карте они находятся в двух первых столбцах и отвечают на вопросы «Кто/что» и «Какой/Какая».

Открываю Key Collector, активирую пакетный сбор из левой колонки, ставлю ключевые слова, по которым и будет собираться основа семантического ядра.
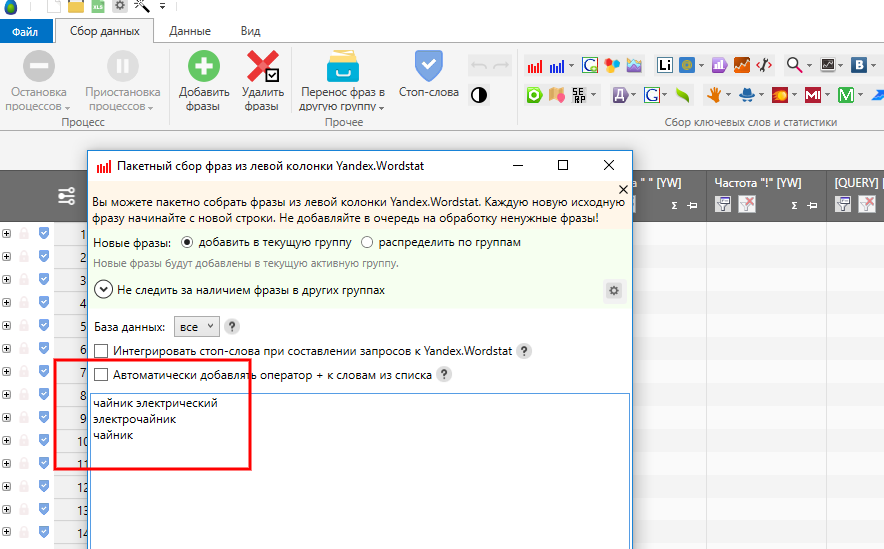
С целью максимального расширения ядра вы можете парсить запросы не только из Яндекса.Wordstat. Расширить семантику можно за счет сбора подсказок поисковых систем, также можно использовать статистики запросов Google, Mail и так далее.
Обработка и очистка собранных запросов от мусора
На сегодняшний день сервисов, позволяющих собрать семантическое ядро более чем достаточно.
Но удобно и быстро обработать собранное ядро порой бывает проблематично. Здесь на выручку приходит конструктор рекламных кампаний UTA-manager.
UTA позволяет быстро почистить семантическое ядро от мусора, выделить списки минус-слов, создать релевантные группы объявлений.
Более того, сервис поможет составить релевантные объявления для каждой группы запросов, подойдет как для Яндекс.Директ, так и для Google Ads, но об этом поговорим немного позже.
Пока мы с вами обсуждали нюансы, Key Collector сделал свою работу и собрал 4 085 фразы.
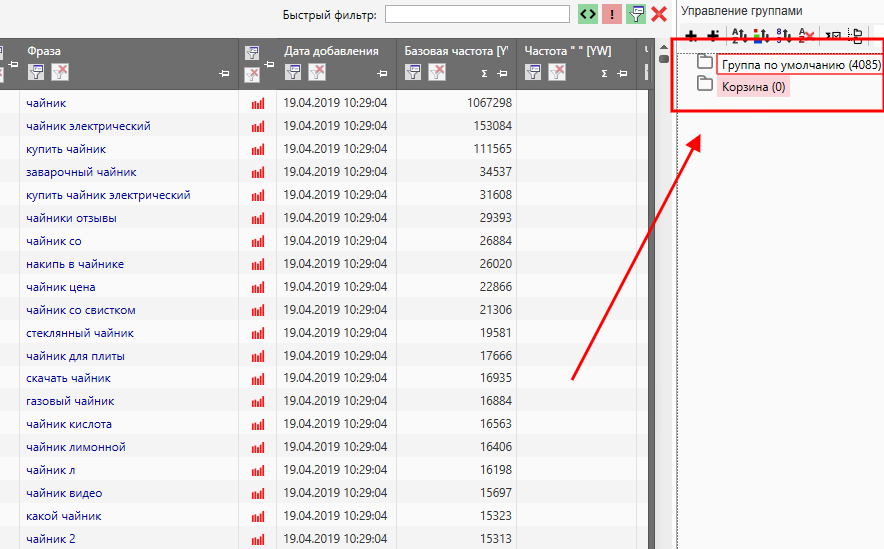
Добавляем собранную семантику в конструктор UTA-manager
Подготовка сервиса к работе
Переходим в UTA-manager. Стоимость использования составляет от 15 до 50 руб. в день, в зависимости от выбранного тарифа. Если у вас семантическое ядро до 50 фраз, вы можете пользоваться конструктором БЕСПЛАТНО.
Копируем фразы из Key Collector в буфер обмена и создаем в ЮТА новый список ключевых слов.
Для списка вводим название и вставляем фразы в соответствующее поле.
Плюс система дает возможность предварительно очистить дубли ключевых запросов, что позволит сэкономить время.
- Подробнее о том, как исключить дубли здесь
Жмем кнопку «Создать» и переходим в конструктор.
Нас встречают три таблицы.
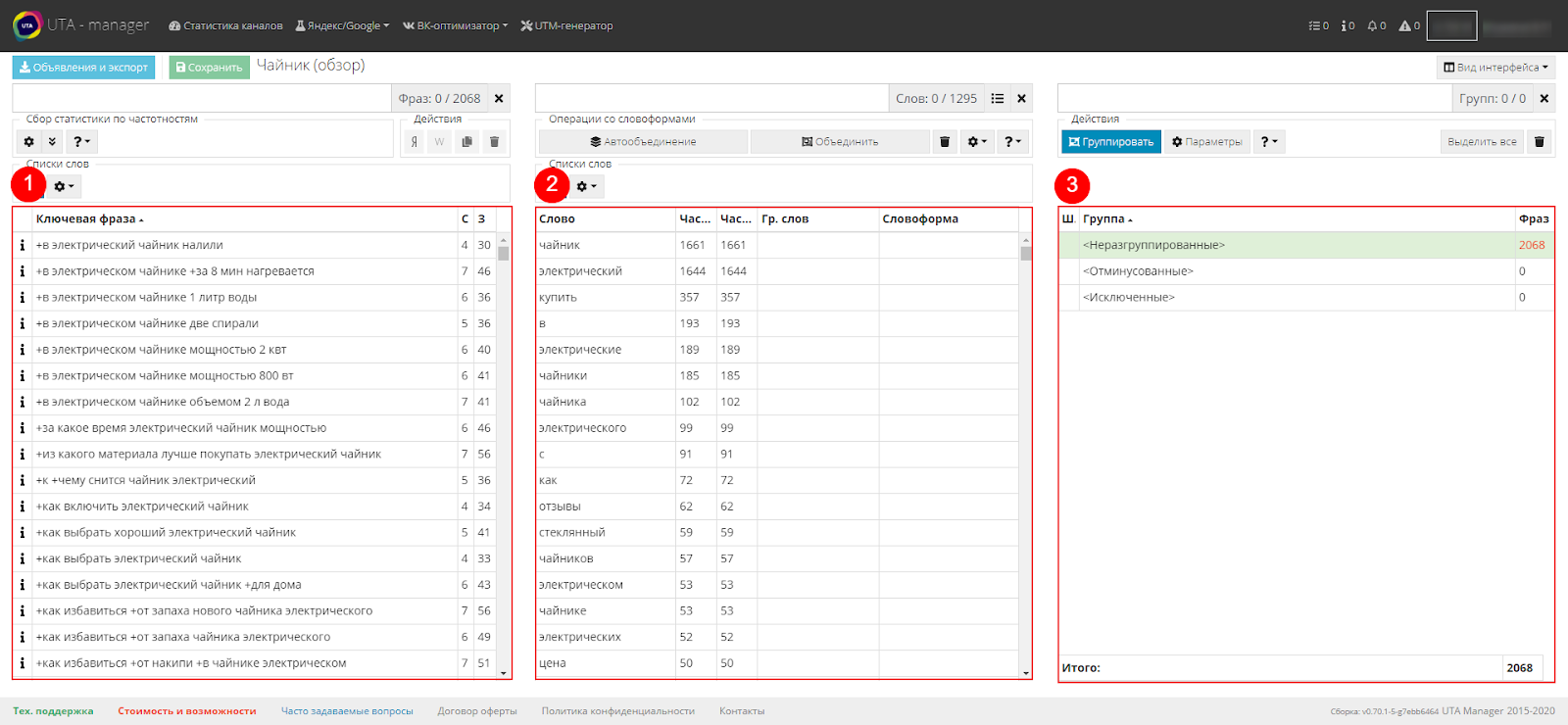
В первой видим ключевые фразы, их 2 068 штук.
Система разбила все фразы на слова и вывела их во второй таблице, при этом уникальных слов получилось всего 1295 штук.
Получается вполовину меньше, чем фраз, значит обработка займет вполовину меньше времени, что не может не радовать.
В третьей таблице после группировки будут отображаться группы ключевых фраз, о них мы поговорим позже.
Для очистки семантического ядра нам понадобится список, в который будем собирать минус-слова.
Над второй таблицей находим кнопку «Списки слов», жмем на знак “+” и из выпадающего меню выбираем «Создать список слов». Вводим название нового списка.
Я его всегда называю знаком «-», чтобы сэкономить место.
Вновь созданный список появится над первой и второй таблицей.
Это сделано для того, чтобы одинаково удобно добавлять слова как из первой таблицы, так и из второй.
Попробовав один раз данную технологию, вы уже никогда не сможете от нее отказаться)))
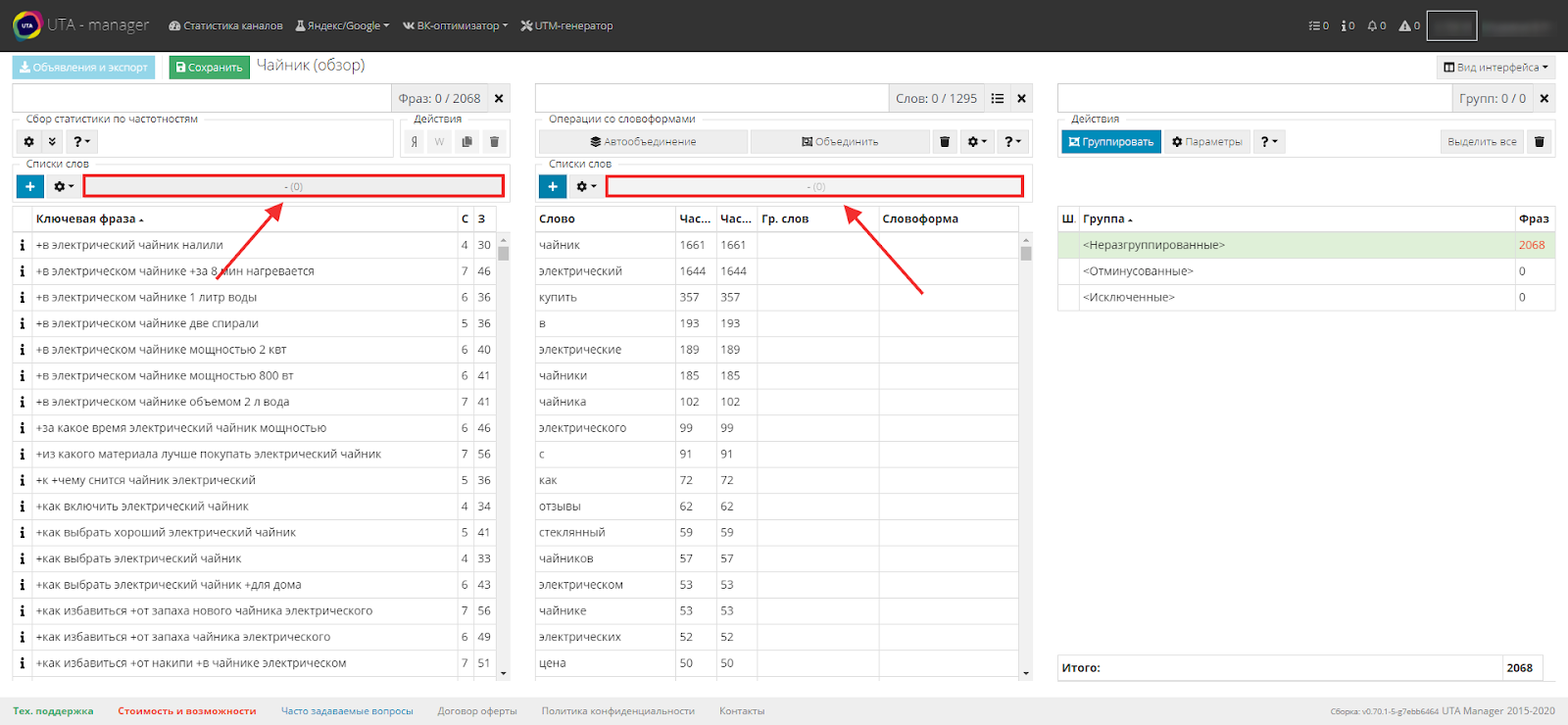
Как видно на скриншоте, рядом с названием списка в скобках отображается цифра. Это количество слов, добавленных в тот или иной список.
Для комфортной работы выполним еще одно подготовительное действие.
Объединим словоформы. Это позволит сэкономить трудозатраты на обработку семантического ядра.
Над второй таблицей активируем операции со словоформами.
“Автообъединение” позволит обработать весь список, а кнопка “Объединить” совместит выделенные слова.
Функционал каждой кнопки мы рассмотрим по ходу действия на практике.
Начнем с первой, жмем ее.
После чего система выведет предупреждение о том, что собирается заново пересоздать словоформы, поэтому если вы вносили дополнительные правки, они будут перезаписаны. Будьте внимательны с этим.
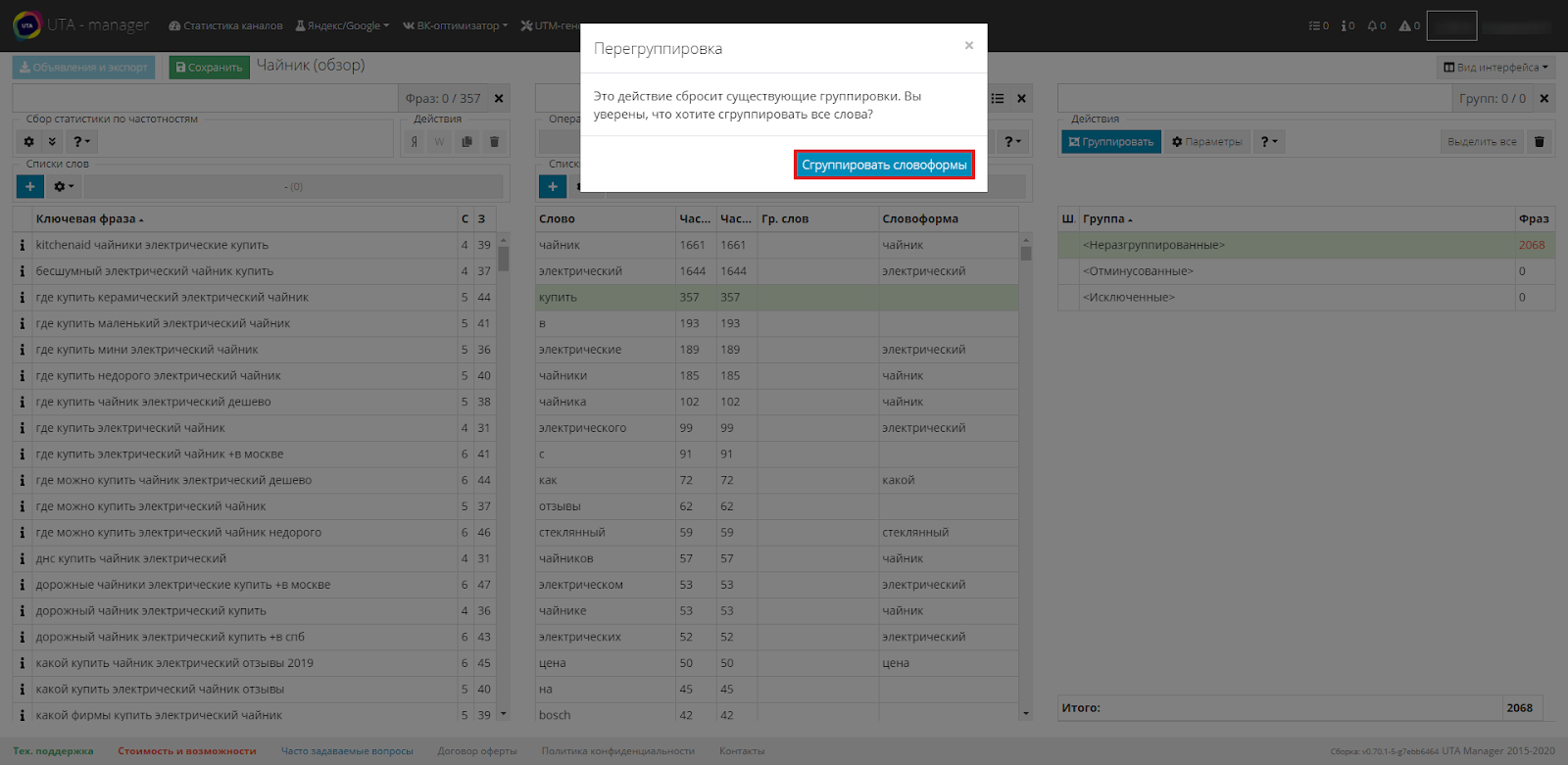
Чтобы избежать двойной работы, рекомендую объединять словоформы в самом начале процесса обработки ядра.
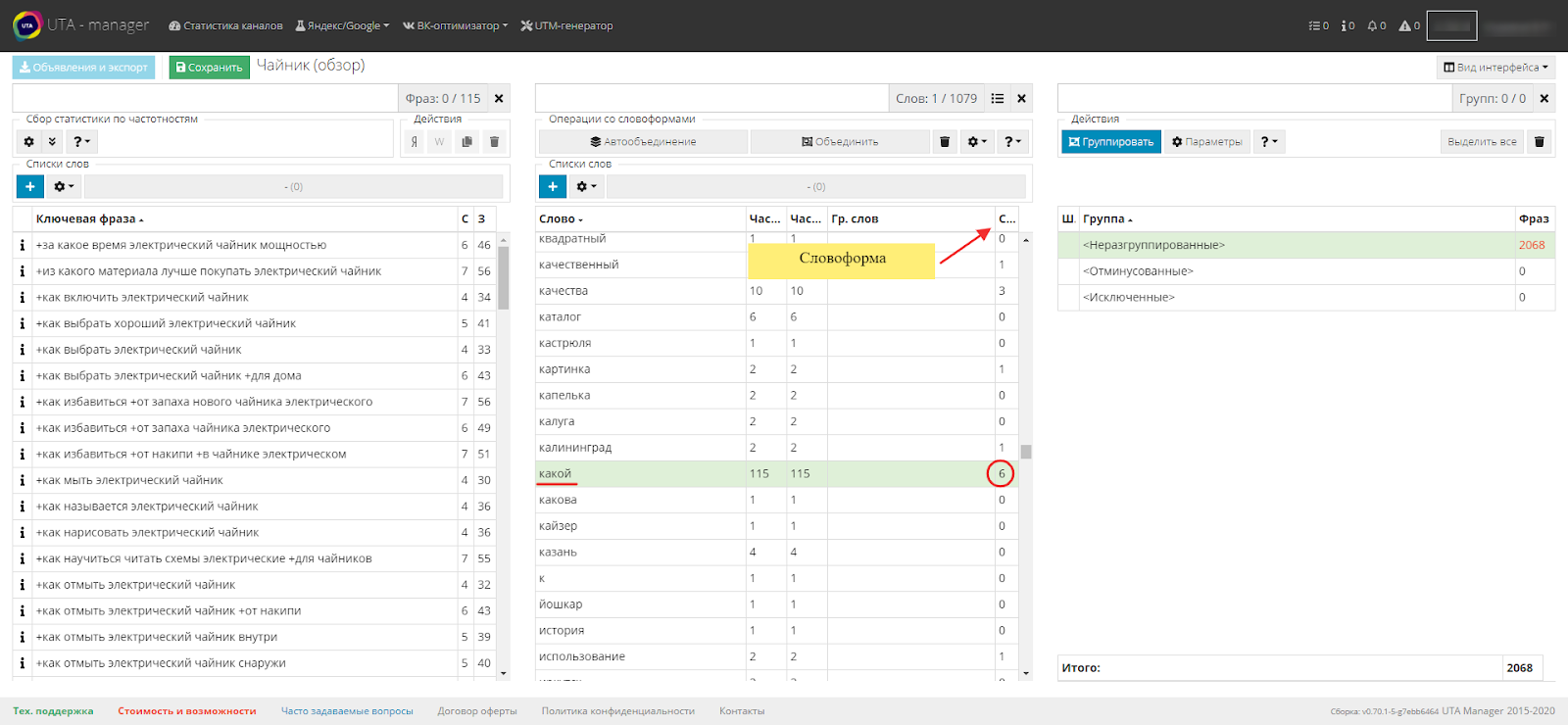
Итак, система объединила словоформы. Теперь наша задача - просмотреть их на соответствие и, если необходимо, внести корректировки. Для этого сортируем по столбцу "Словоформа" и просматриваем, что получилось, проскролливая весь список.
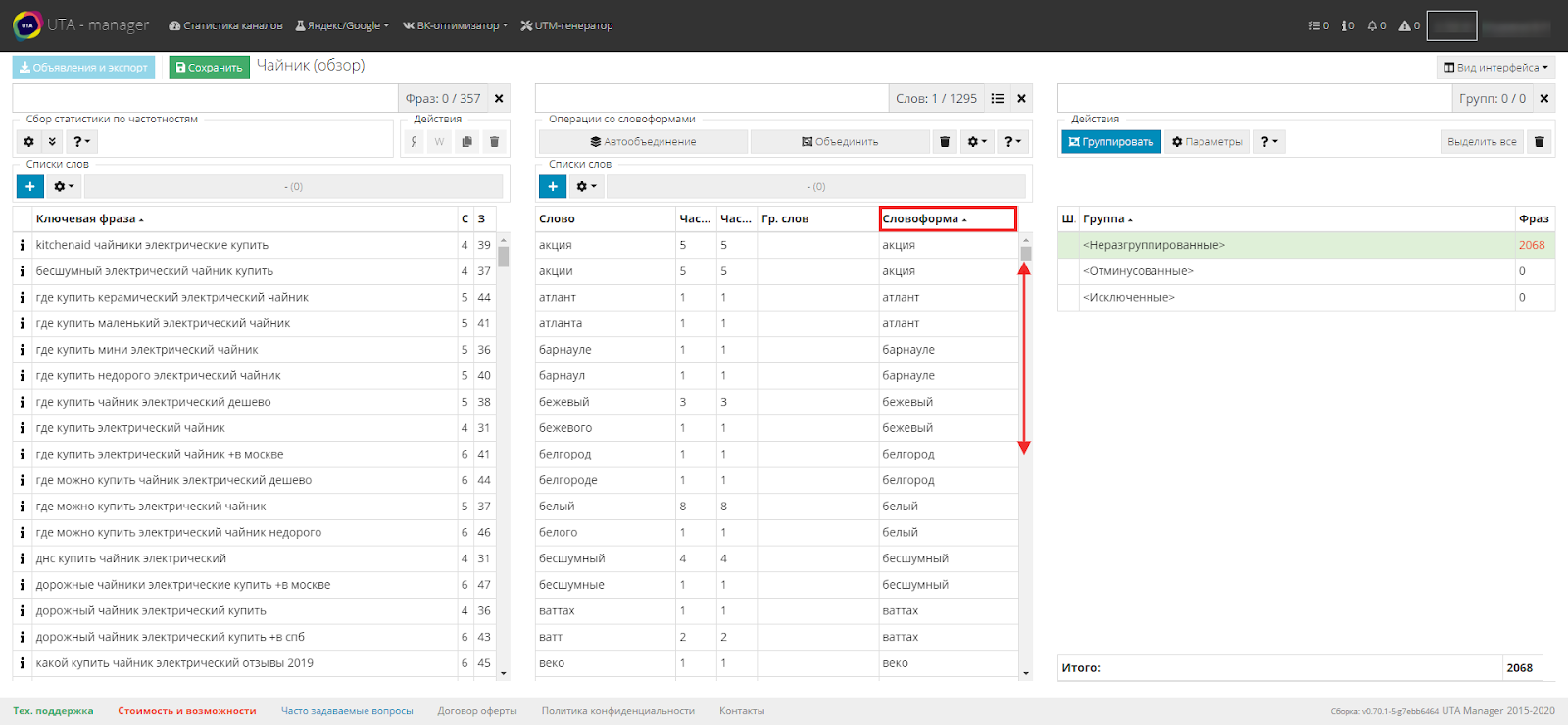
Если найдется слово, которое не по назначению попало в группу словоформ, выделите его и с помощью первой кнопки удалите из группы.
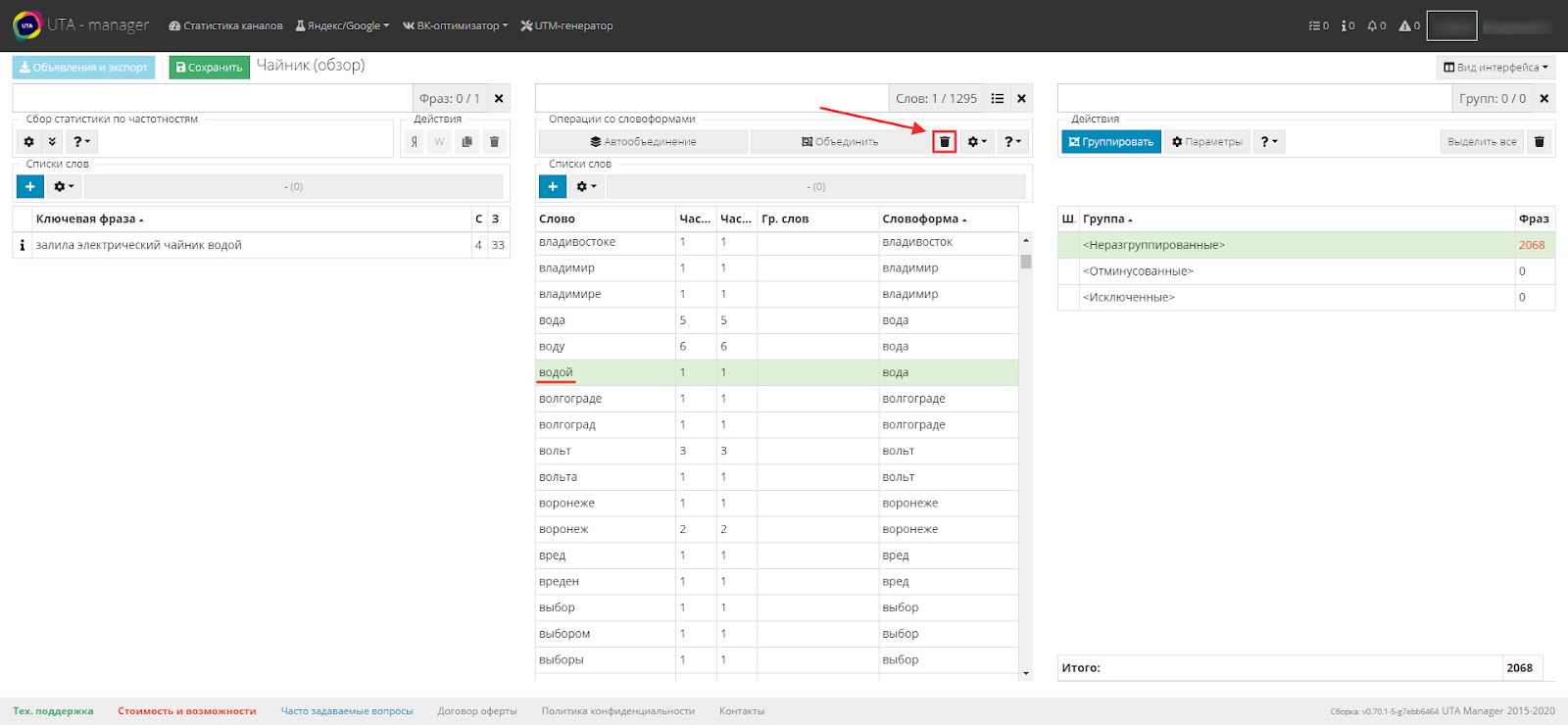
После обработки словоформ, для интереса, нажмите четверную кнопку с глазом. Это позволит увидеть количество оставшихся уникальных слов после объединения словоформ.
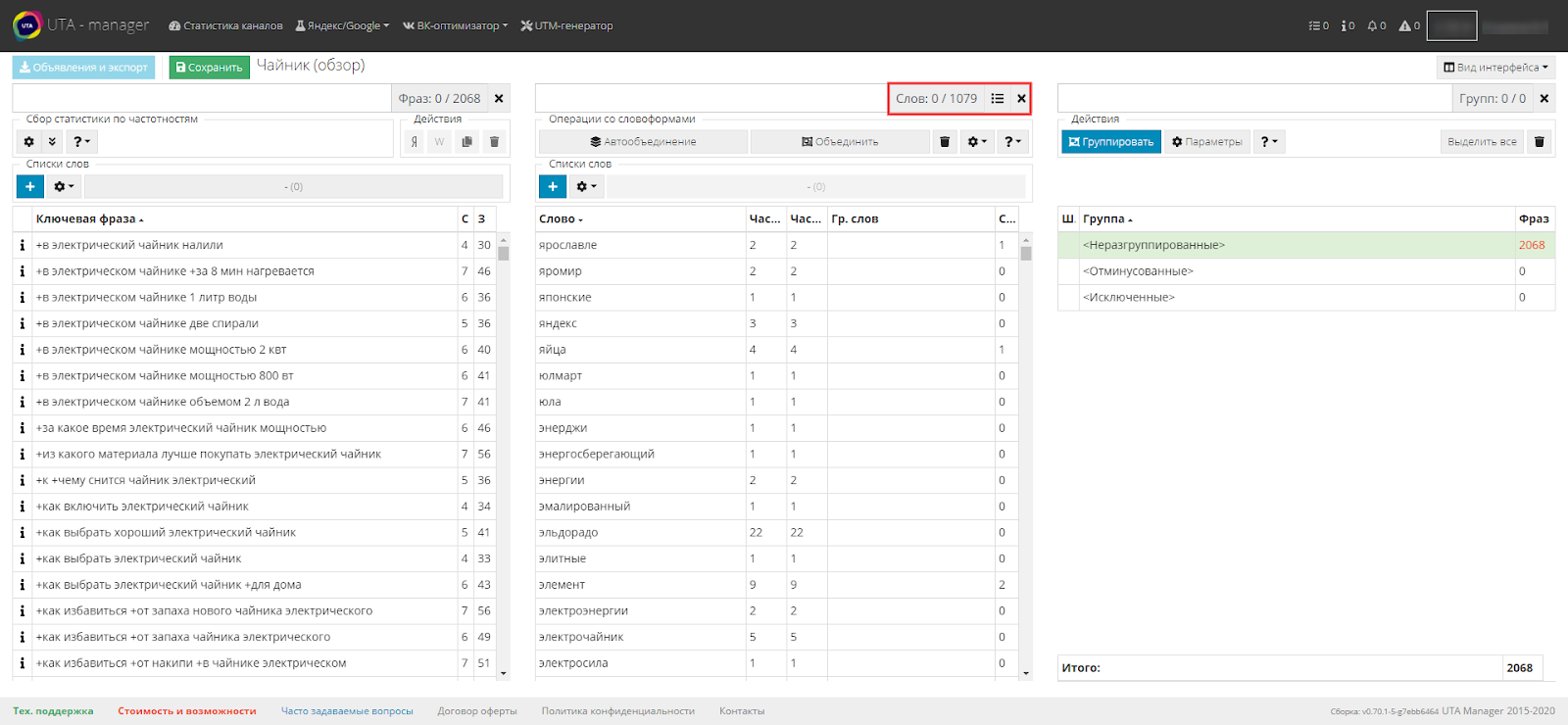
Как мы видим, количество слов значительно уменьшилось. Получается, что на входе у нас было чуть более 2000 фраз, которые мы преобразовали в 1079 слов, тем самым уменьшили количество обрабатываемой информации более чем в два раза.
Рядом с каждым словом в столбце «словоформа» отображается число, означающее сколько в том или ином слове словоформ.
Приступаем к очистке
Подготовительные работы выполнены, со словоформами разобрались, теперь можно переходить к минусации.
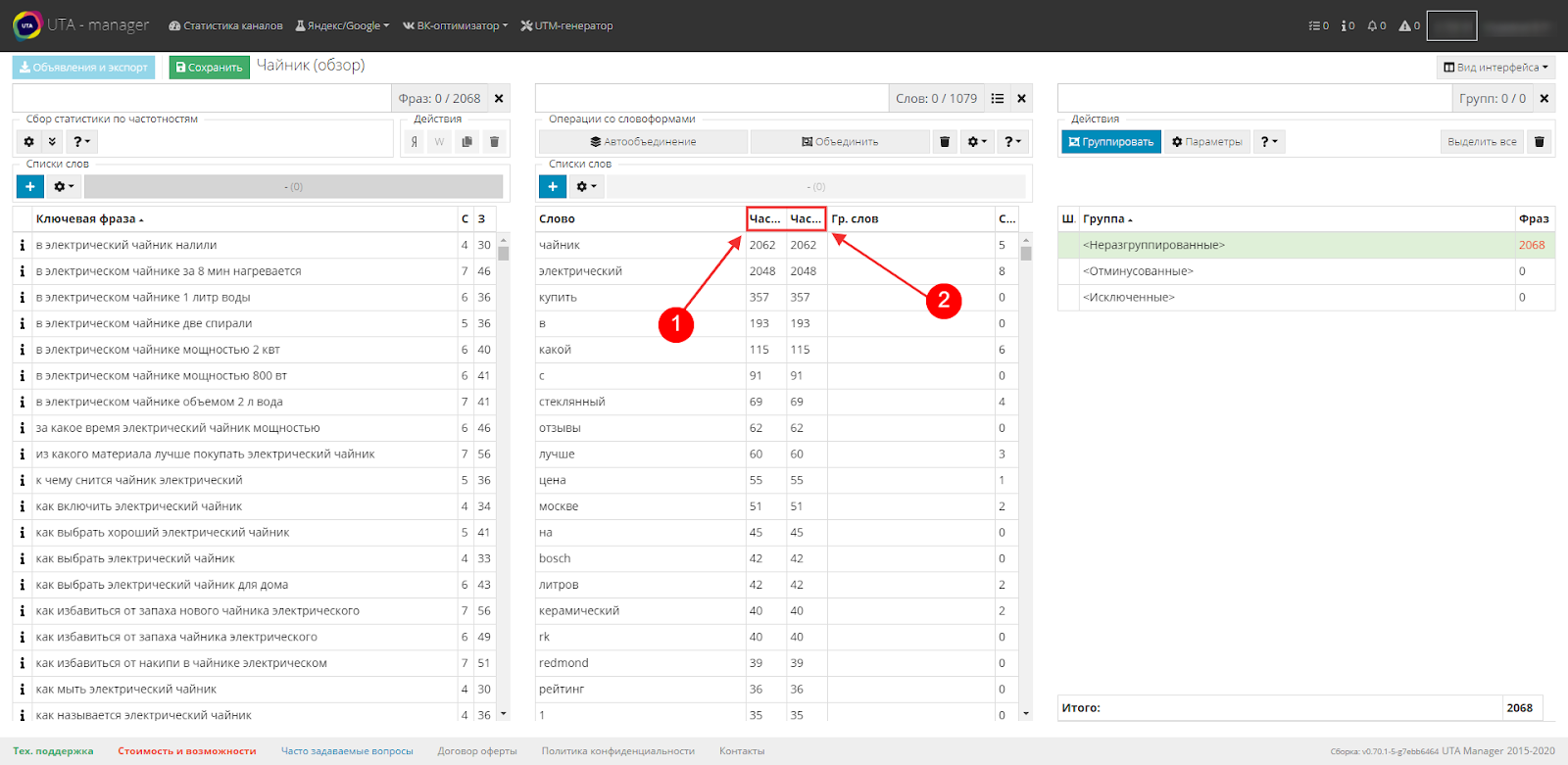
Обратите внимание, во второй таблице показана частотность слова в выделенных группах, о нем мы поговорим позднее на этапе группировки.
А соседний столбец показывает частотность по всему семантическому ядру.
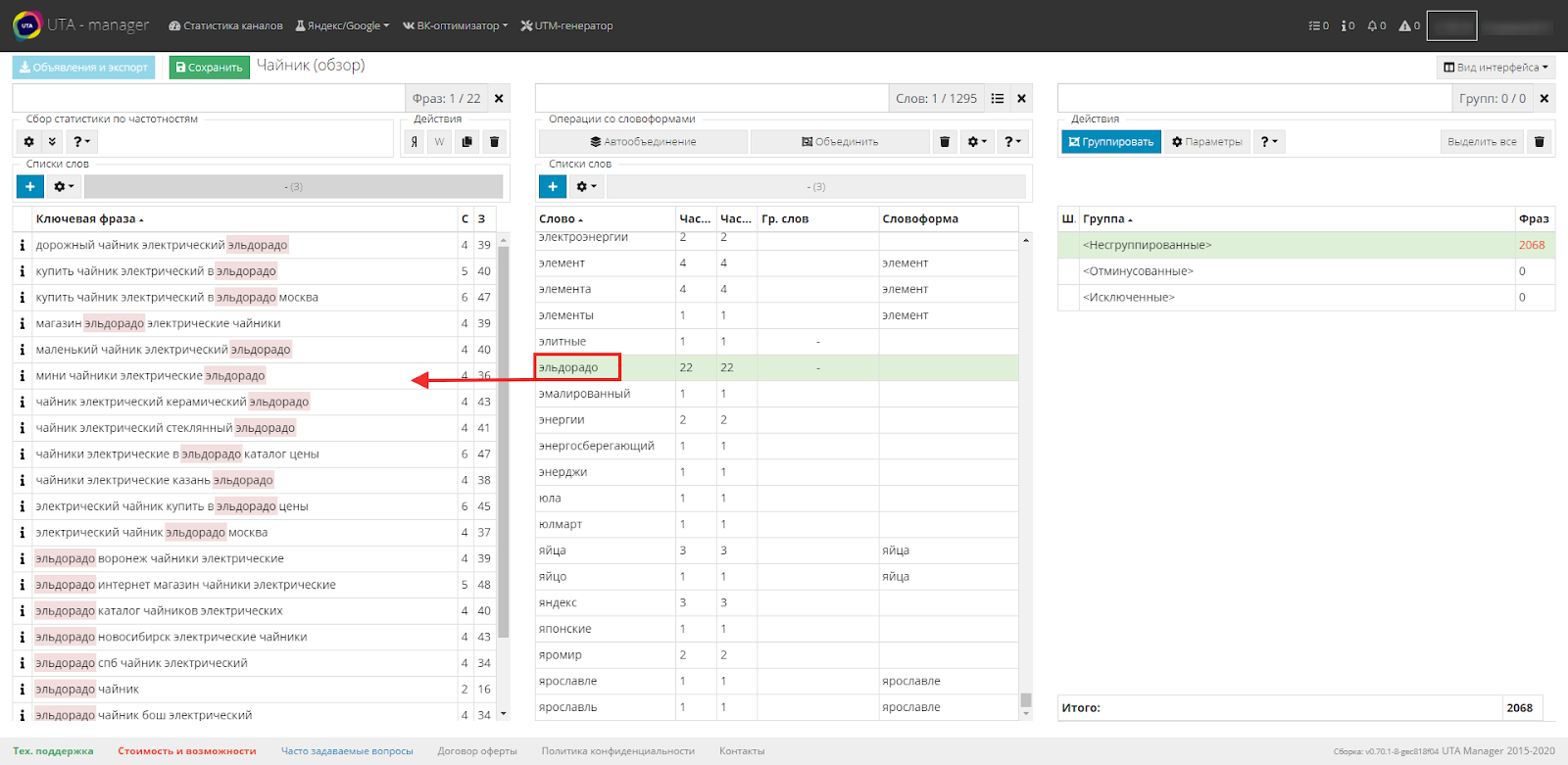
Начнем с простого, во второй таблице в столбце «Слово» находим первое, которое вызывает сомнения.
В нашем случае это будет «Своими».
Опытный специалист сразу поймет смысл фразы с употреблением данного слова, но чтобы убедиться, выделяем его.

Как видим, в первой таблице система вывела все фразы, содержащие выделенное слово.
Это позволяет быстро понять смысл и состав фраз и принять решение о добавлении последнего в список минус-слов.
Для того чтобы добавить слово в список минус-слов, над центральной таблицей жмем на соответствующий список.
В результате наблюдаем, что количество содержащихся слов в списке поменялось, а рядом со словом появилось название списка, в котором содержится слово.

По частотности слова мы понимаем, что 2 фразы, содержащие слово «своими», отправляется в минус.
Параллельная минусовка
Теперь следующий лайфхак: «Параллельная минусовка».
Обращаем внимание на первую таблицу и активируем стоящий над ней список «-».

Как видите, после этого все слова, содержащиеся в активированном списке, засветились красным.
Получается так: вы нажимаете на слово во второй таблице для того, чтобы посмотреть фразы, в которых оно встречается. Активируете список минусов и в первом столбце нажимаете на слово, которое автоматически выделится во всех фразах. Такой подход значительно упрощает ваш труд при очистке семантического ядра.
Обратите внимание, выделять минус-слова вы можете в любом удобном для вас сценарии - либо из второй таблицы, либо из первой.
Я всегда комбинирую, так получается быстрее, и процесс не такой занудный.
Анализ вложенности фразы
С минусами разобрались, но остались нюансы.
Как быть, если непонятно, куда отнести слово, и хотелось бы более детально его изучить? Например, посмотреть вложенность в Wordstat или изучить выдачу по фразе, содержащей определенное слово.
UTA-manager поможет решить и эти вопросы.
Над первой таблицей снимаем активацию списка, выделяем необходимую фразу, в результате чего фраза подсветится зеленым (если этого не произошло - проверьте, скорее всего вы не сняли активацию списка).
Над таблицей под строкой фильтра находим иконки действия.
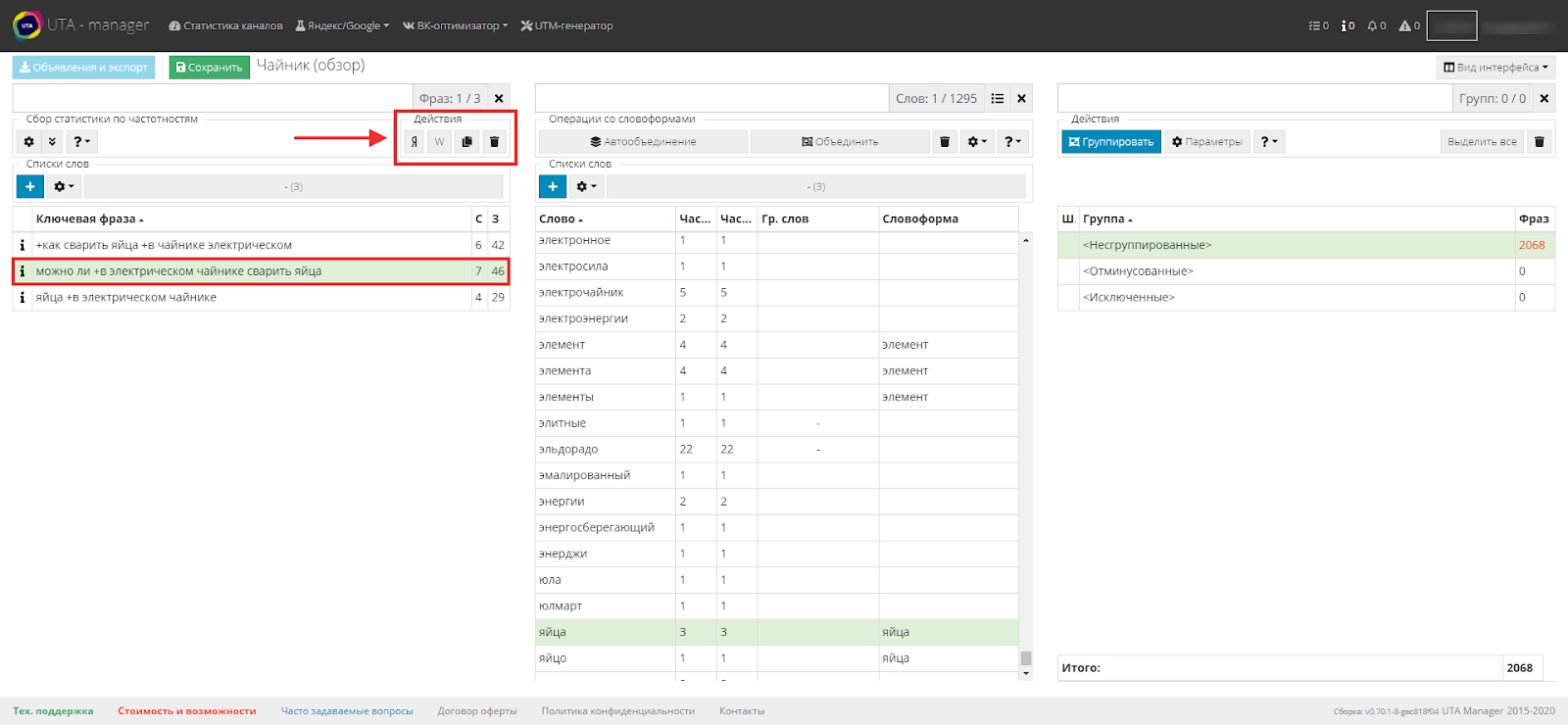
- первая откроет выделенную фразу в выдаче в поисковой системе Яндекс;
- вторая откроет фразу в Wordstat;
- третья копирует в буфер обмена;
- четвертая удалит фразу насовсем из собранного семантического ядра.
Как исключить фразы с минус-словами из основного списка
С анализом разобрались, приступим к исключению фраз, содержащих минус-слова.
Этот прием можно использовать на любой стадии группировки.
Переходим к третьему столбцу, в правом верхнем углу находим и жмем шестеренку или используем горячую клавишу «I».
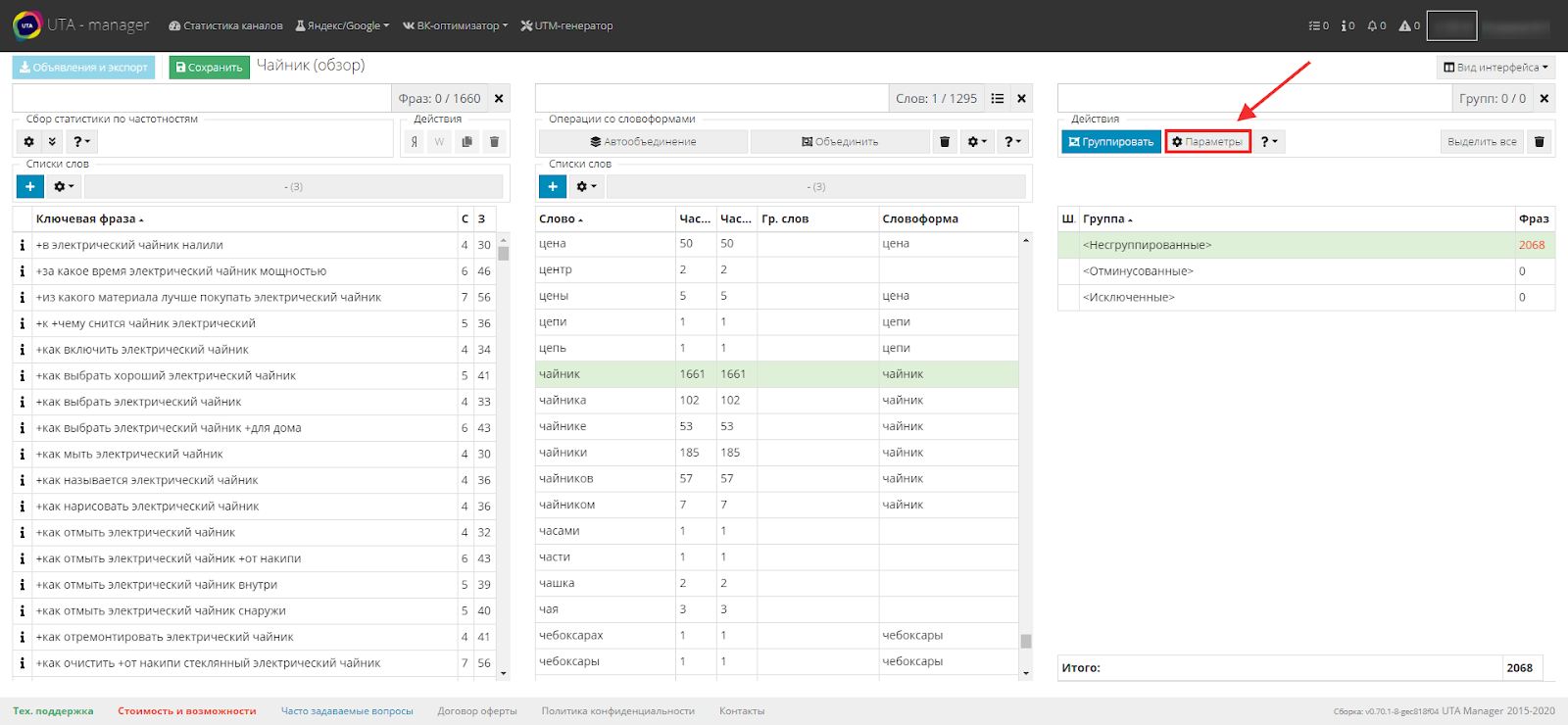
Во всплывающем окне вы увидите настройки группировок. Система имеет два режима - обычный и расширенный, с последним мы познакомимся немного позднее.
В настройках условий группировки видим два поля, изменяя которые мы влияем на результаты группировки.
Если кратко, то это означает - на основании скольких похожих слов во фразе будут формироваться группы. Но об этом позднее.
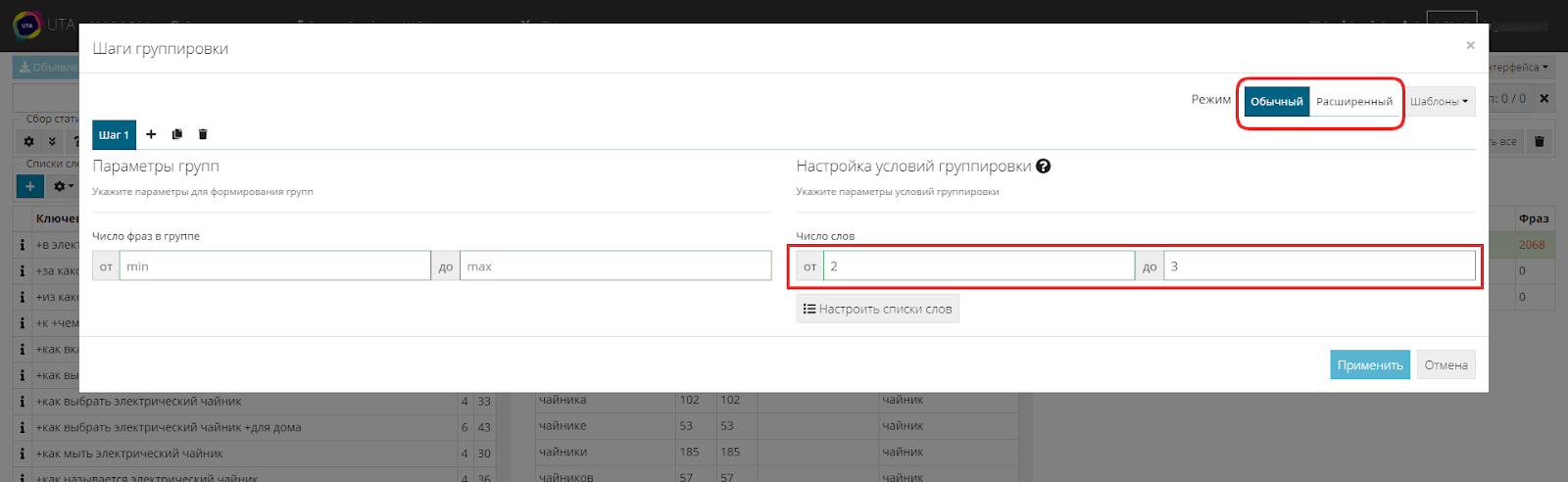
Сейчас наша задача - создать невыполнимые условия, для того чтобы система не группировала ядро, и все фразы остались в едином списке несгруппированных. Но при этом фразы, содержащие минус-слова, должны уйти в отминусованные.
Для этого в настройках условий группировки ставим нулевое значение.
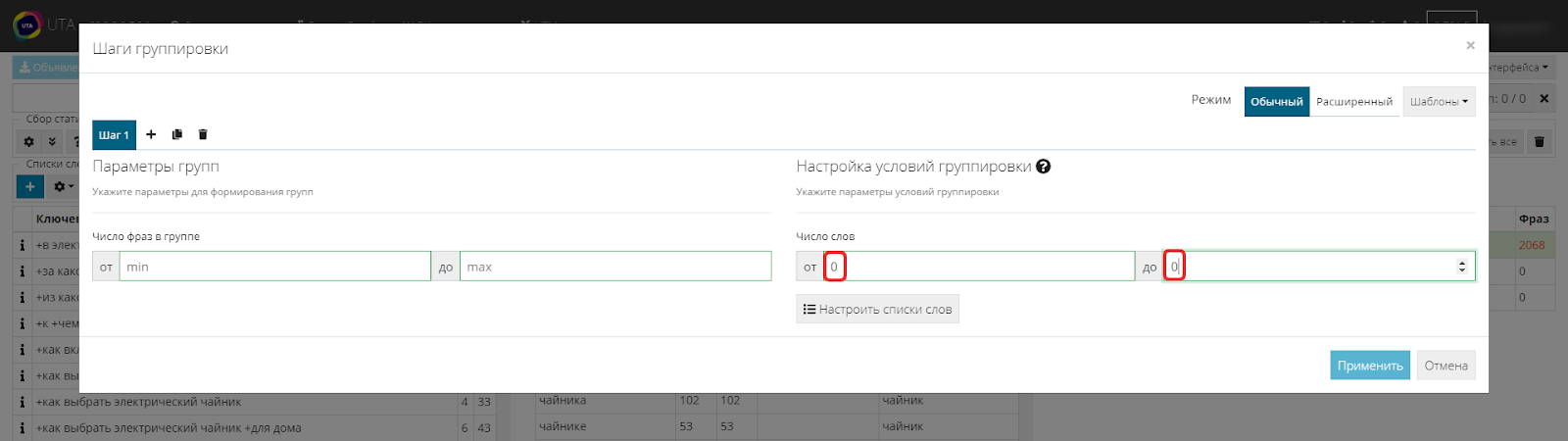
Теперь к алгоритму нужно добавить ранее собранный список минус-слов. Для этого жмем кнопку «Настроить списки» и выбираем необходимый.
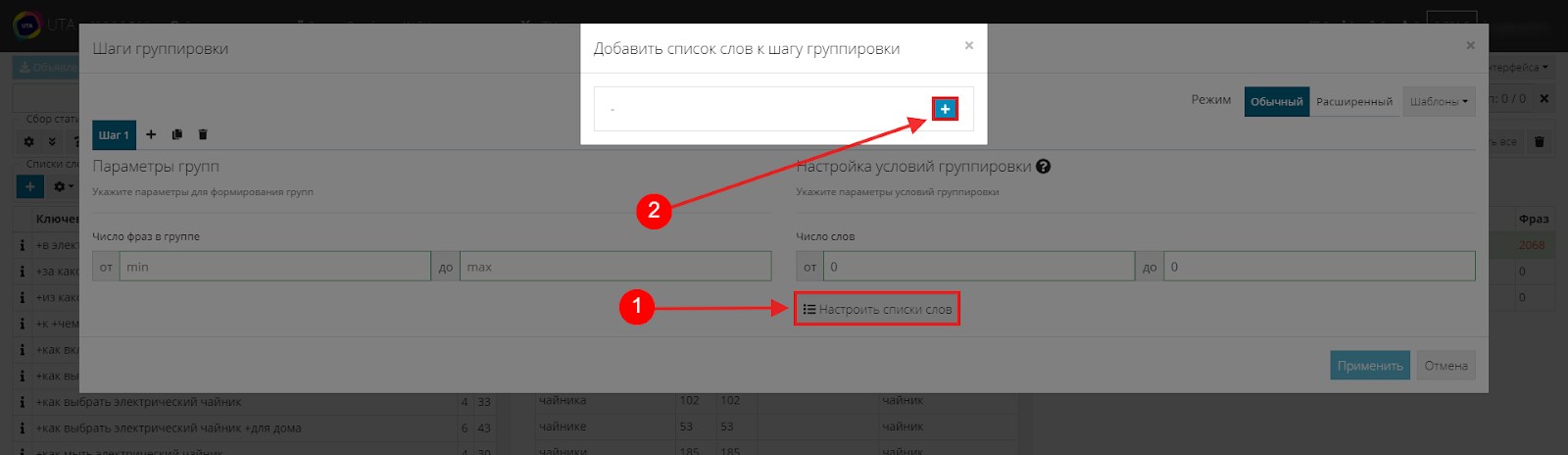
Далее в настройках выбираем значение «Минус-слова», это назначит команду системе, что все фразы, содержащие слова из этого списка, необходимо отправить в “Отминусованные”.
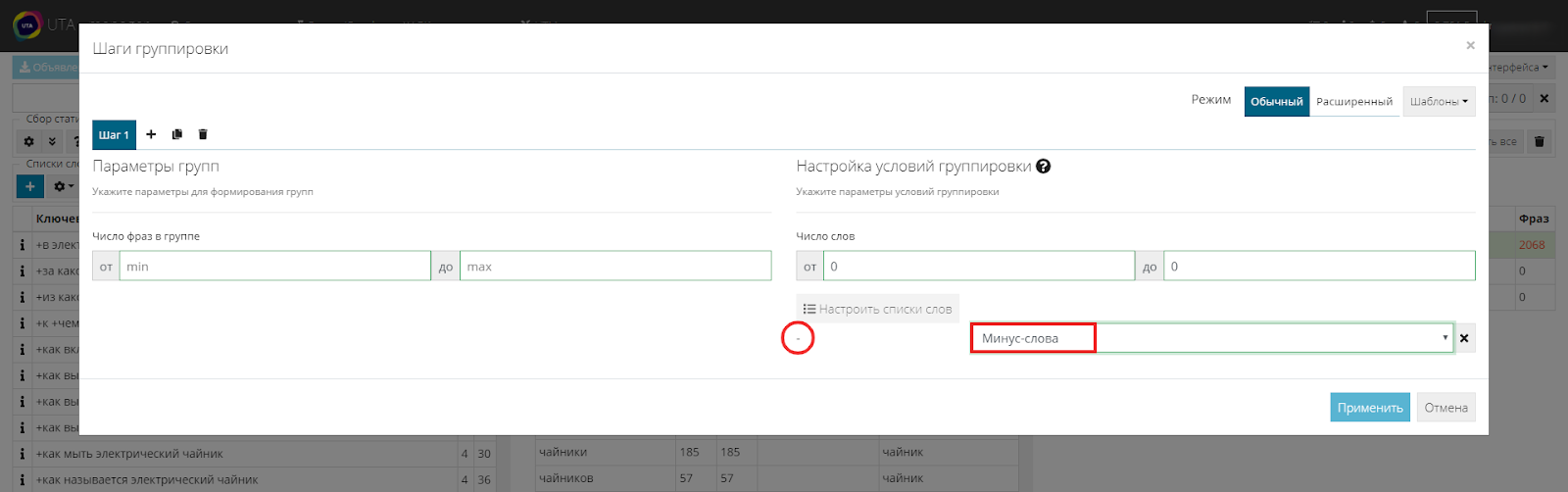
Жмем "Применить" и переходим в основной интерфейс.
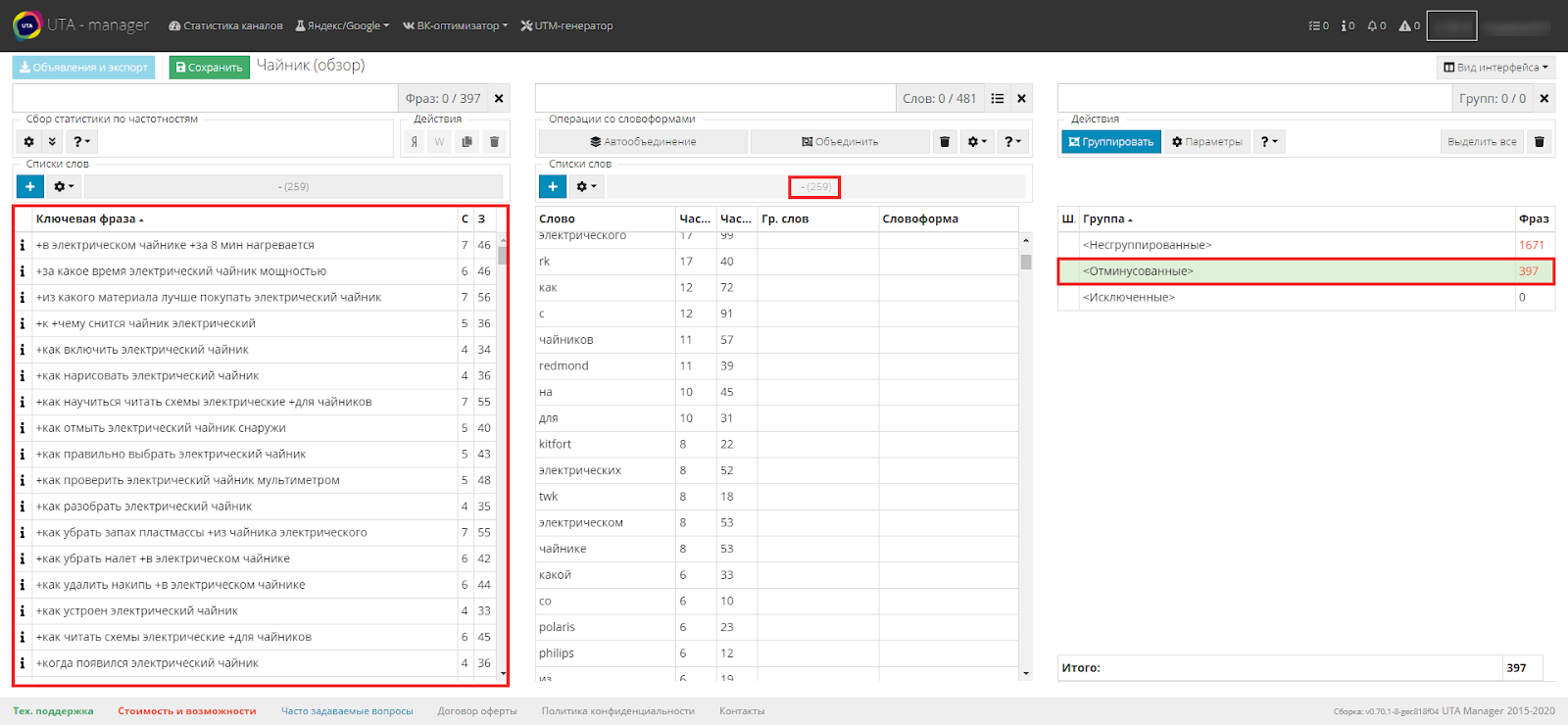
Обратите внимание на третью таблицу. Несгруппированных фраз у нас 2068 шт., остальных по нулям.
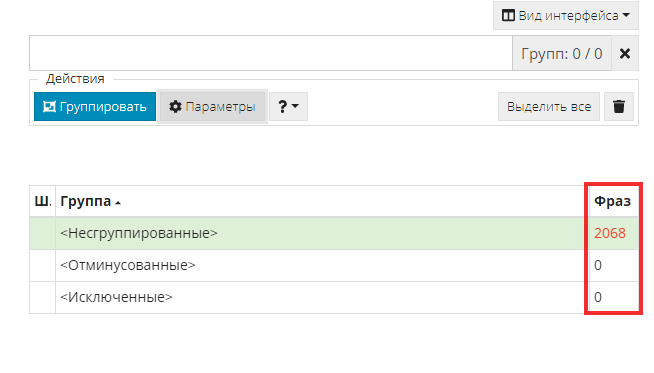
Посмотрим, как эти цифры изменятся после обработки.
В левом верхнем углу находим кнопку «Группировать» или используем горячую клавишу «R».
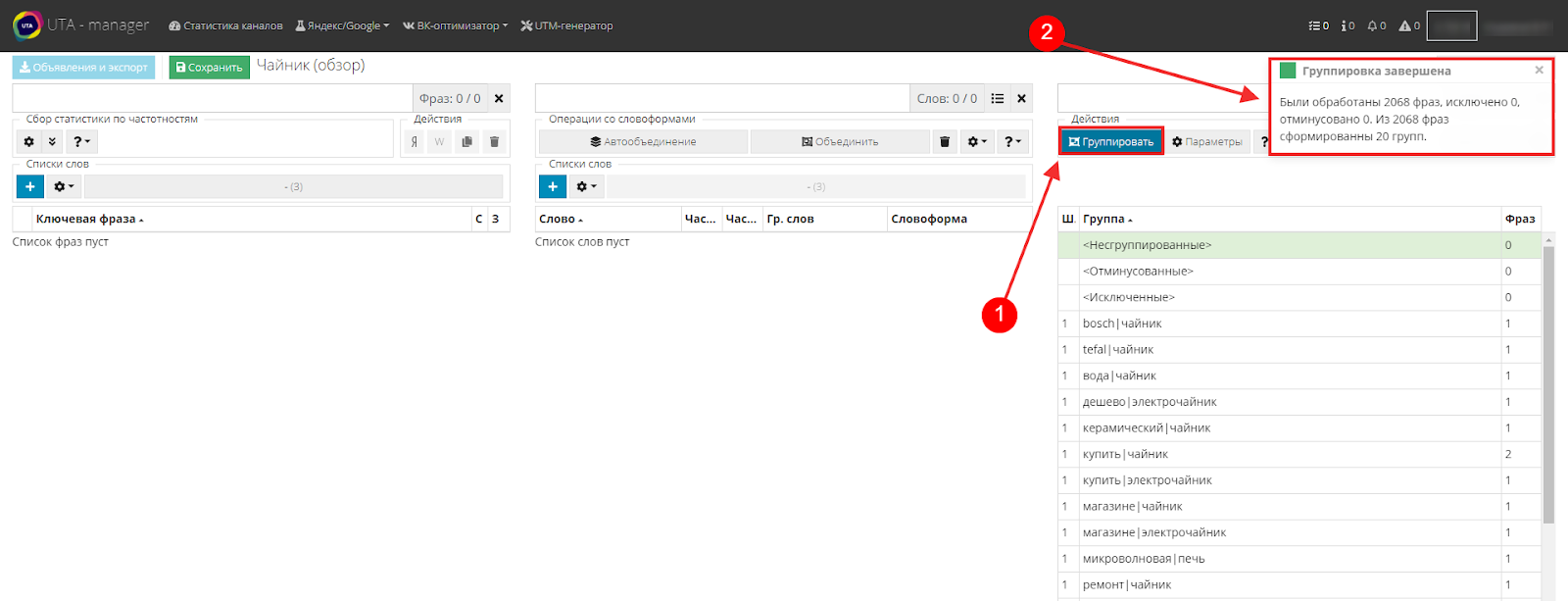
После успешного выполнения система выдаст сообщение об успешно выполненной задаче.
В результате, как вы можете увидеть, в третьей таблице изменились значения.
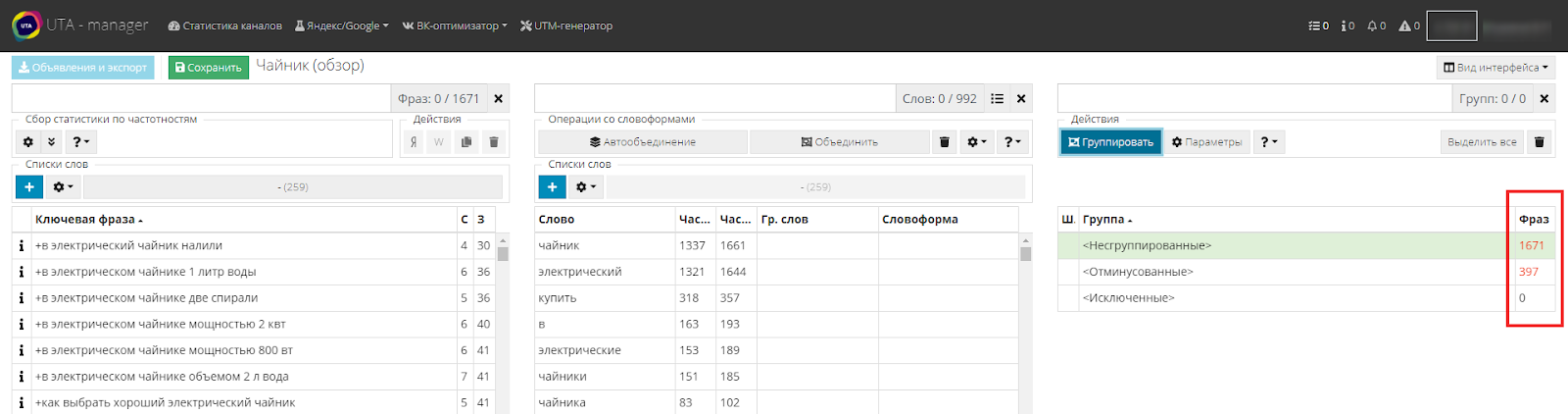
Несгруппированных осталось 1 671 шт., а отминусованных стало уже 397 шт.
Получается, что слова, которые мы ранее добавили в список минусов, содержались в 372 фразах. Это можно легко проверить, нажав на группу «Отминусованные», и посмотреть во вторую и первую таблицу.
Теперь ваша задача - самостоятельно пройти все семантическое ядро и максимально дополнить список минус-слов. Затем собранный список можно будет скачать и добавить в рекламную кампанию Яндекс.Директ.
Объединяем одинаковые слова (русский и латинский транслит)
Если перед работой с семантическим ядром вы предварительно готовились, то количество работ еще больше сокращается.
Вспоминаем про нашу карту запросов и задачи, которые перед нами стоят.
В первую очередь займемся марками, так как эту задачу проще и быстрее выполнить, потому что данные по маркам, которые есть в наличии, у нас уже собраны. Нам остается только добавить их в систему и выделить запросы, содержащие марки чайников, которые есть в наличии. Далее методом исключения выделим марки, которых у нас нет и сразу выполним вторую задачу.
Но давайте по порядку. Сначала добавим марки электрочайников в систему и объединим похожие слова, так как мы знаем, что покупатели могут спрашивать как на русском, так и на английском.
Для этого я еще на этапе подготовки карты запросов написал названия в двух вариантах.
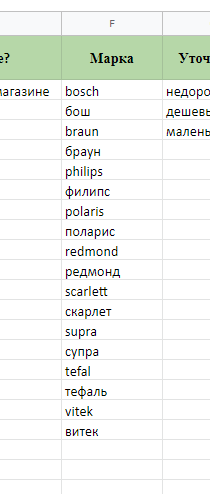
Открываем документ, копируем названия, переходим в UTA-manager.
Над второй таблицей в строке фильтра находим значок многострочного фильтра.
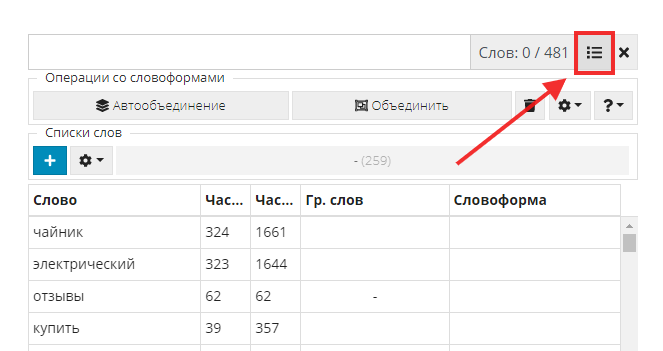
Жмем его и в открывшееся окно вставляем ранее скопированные названия марок.

Жмем кнопку «Применить» и смотрим, что получилось.
Обратите внимание: вводить слова в многострочный фильтр необходимо в нижнем регистре, и в каждой строке должно быть только одно слово.
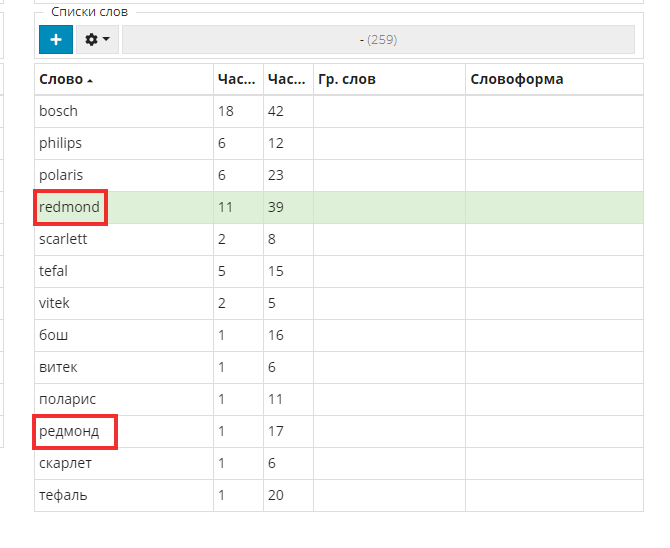
Как видно во второй таблице, система отфильтровала найденные слова. Теперь наша задача - объединить названия на разных языках в одну словоформу, чтобы UTA их понимала как одно единое слово. Это позволит сделать более плотные группы и сэкономить время на дальнейшей настройке.
Процесс объединения слов в разном написании
Во второй таблице выделяем два похожих слова и объединяем их нажатием первой кнопки.
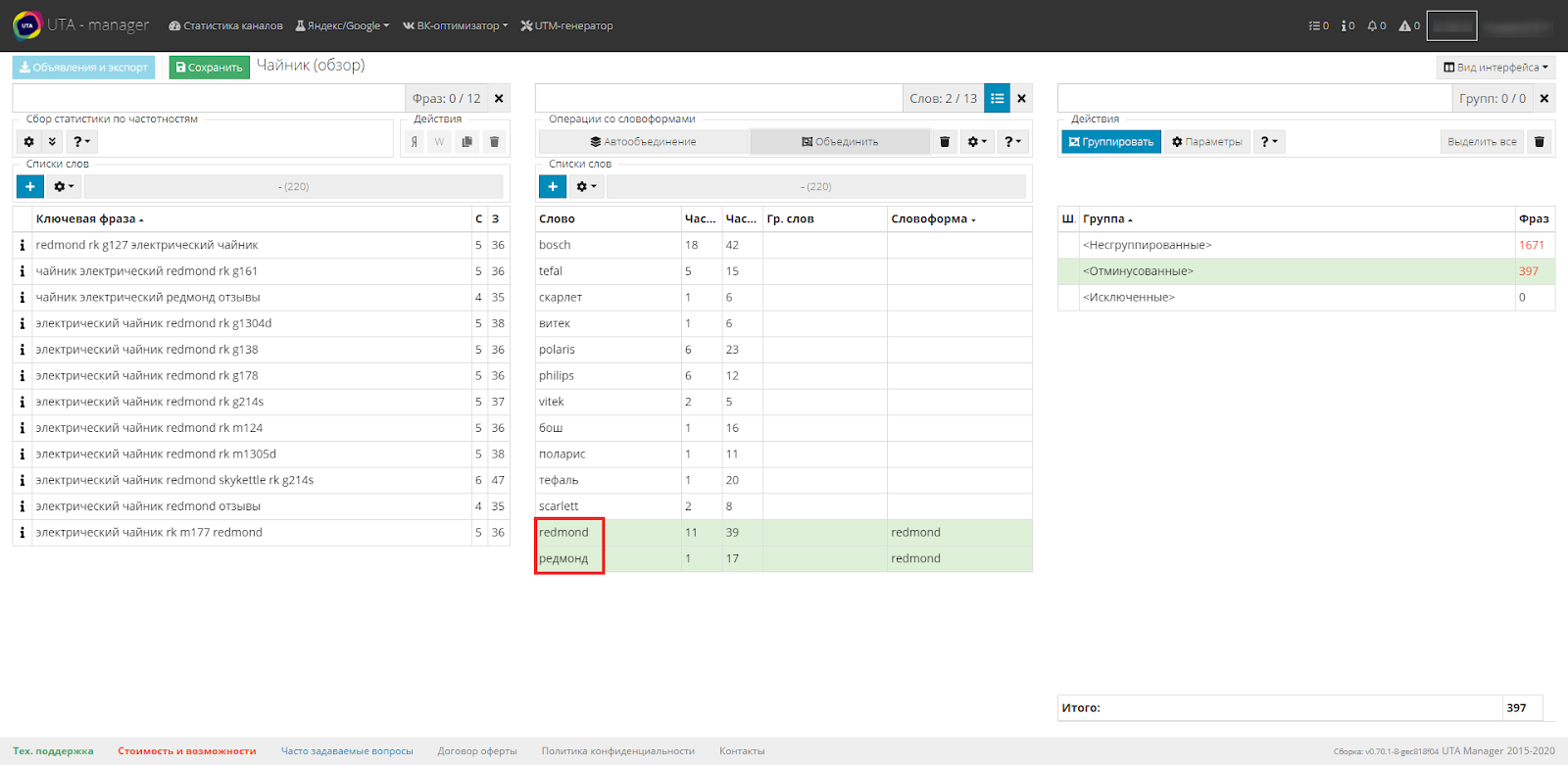
Как видим, система объединила «Редмонд» в одну словоформу.
Проделываем это со всеми словами в таблице.
После того как закончите, не забудьте очистить многострочный фильтр, так как если этого не сделать, то во второй таблице не будут видны остальные слова.
Если фильтр активирован, его иконка горит синим цветом. Для того чтобы его сбросить, нажмите крестик рядом.

В результате этих нехитрых действий мы с вами научились находить и объединять похожие слова. Переходим к группировке.
Группировка семантического ядра по словам из списка
Как вы уже знаете, система умеет группировать в автоматическом режиме по похожим словам.
Но эта группировка на троечку, я ее использую только в крайних случаях, когда необходимо посмотреть, из чего состоит ядро, поэтому на ней акцентироваться не будем. А всем, кому интересно, я записал видеоролик про автогруппировку, смотрим здесь.
Итак, вспоминаем нашу задачу, одно из ее условий «Сделать кампанию, содержащую в себе марки, имеющиеся в наличии»
Для этого создаем еще один список (как это делать вы уже знаете, рассматривал выше). Назовем его «Марки».
Если на этом этапе вы уже сбросили действие многострочного фильтра, вернитесь и активируйте его заново, так как нам нужно добавить наши марки в новый список.
Выделяем отфильтрованные марки и добавляем их в соответствующий список. Как видим, всем словам из списка присвоилась группа «Марки».
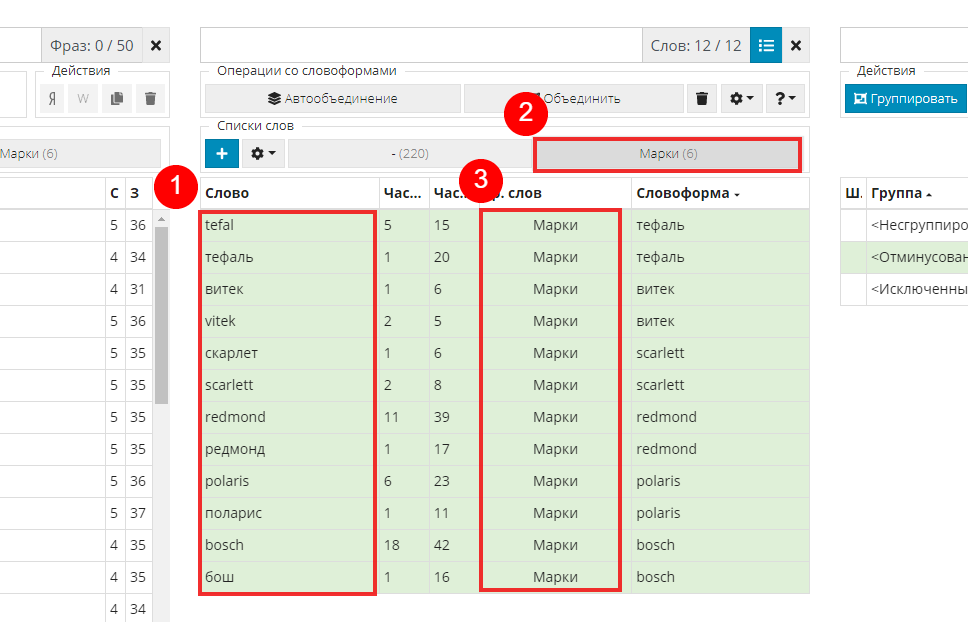
Очищаем действие многострочного фильтра, для того чтобы вернуть таблицу в исходный вид.
Приступим к настройке группировки.
В правом верхнем углу жмем шестеренку, на этапе минусами мы уже пользовались этим функционалом.
Переходим в расширенный режим и видим большое количество настроек. С ними мы разберемся позднее, на данный момент нас интересуют настройки условий группировки.
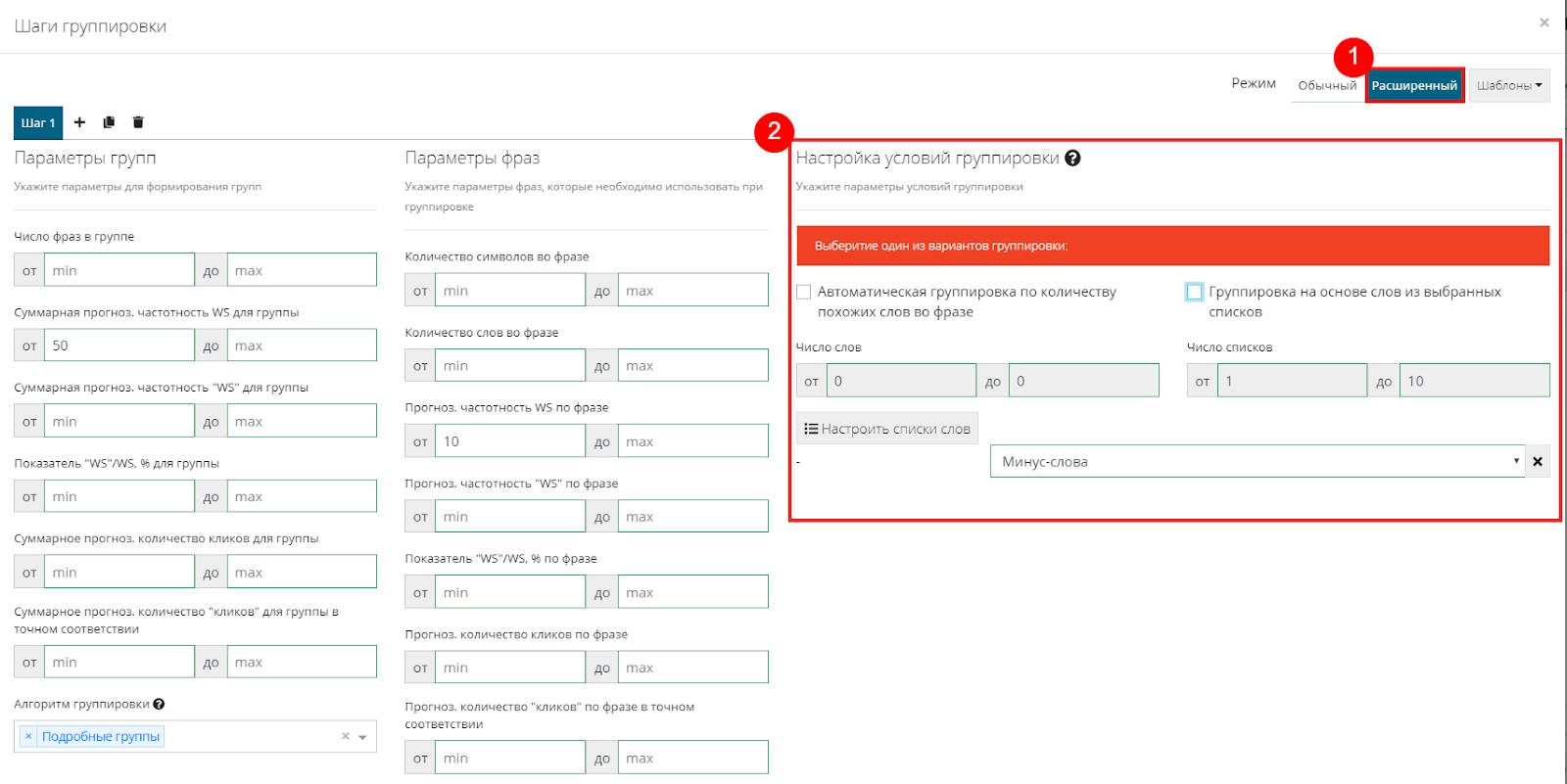
Видим, что система выдает предупреждение о том, что необходимо выбрать один из вариантов группировок.
Так как мы хотим выполнить точную группировку по собранному списку слов, выбираем второй вариант «Группировка по спискам». После выбора UTA-manager изменит предупреждение на пояснение о том, как работает данный режим.

Замечаем, что здесь уже присутствует ранее добавленный список минусов. Мы его так и оставим, мало того, параллельно мы будем его пополнять, для того чтобы оставить только целевые ключевые запросы.
Жмем кнопку «Добавить список» и выбираем «Марки».
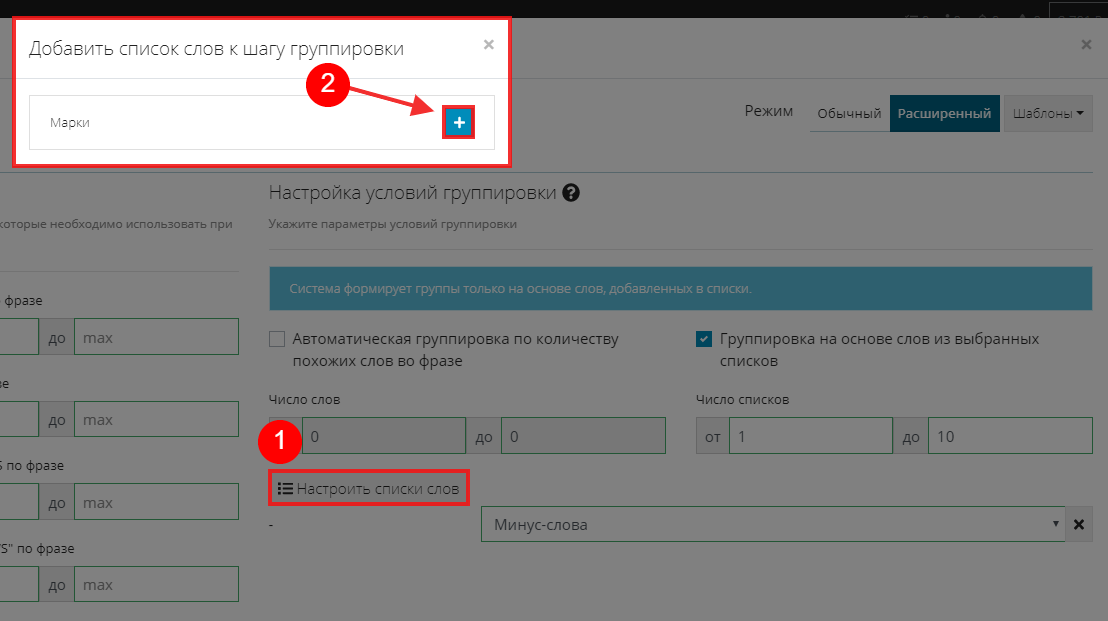
После добавления списка назначаем ему статус «Группообразующий: несколько слов».

Прежде чем нажать «Группировать», давайте представим, какие группы получатся в третьей таблице.
Так как мы используем группировку по спискам, то я ожидаю, что получатся группы, сформированные и содержащие в себе слова из списка. Пробуем - жмем "Группировать" и смотрим, что получилось.
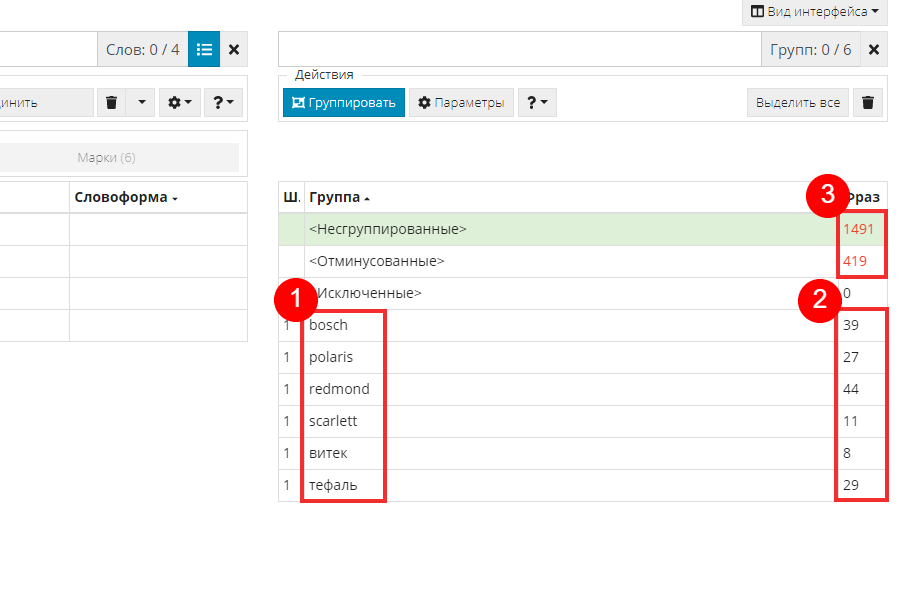
Как и ожидалось, система создала нужные группы.
- Под номером 1 видим названия групп или, другими словами, то слово, на основе которого была создана группа.
- 2 - это количество фраз, содержащихся в группах.
- 3 - это оставшиеся несгруппированные и отминусованные фразы, с которыми нам предстоит еще поработать.
Выделяем первую группу «bosch» и смотрим ее состав во второй и первой таблице.
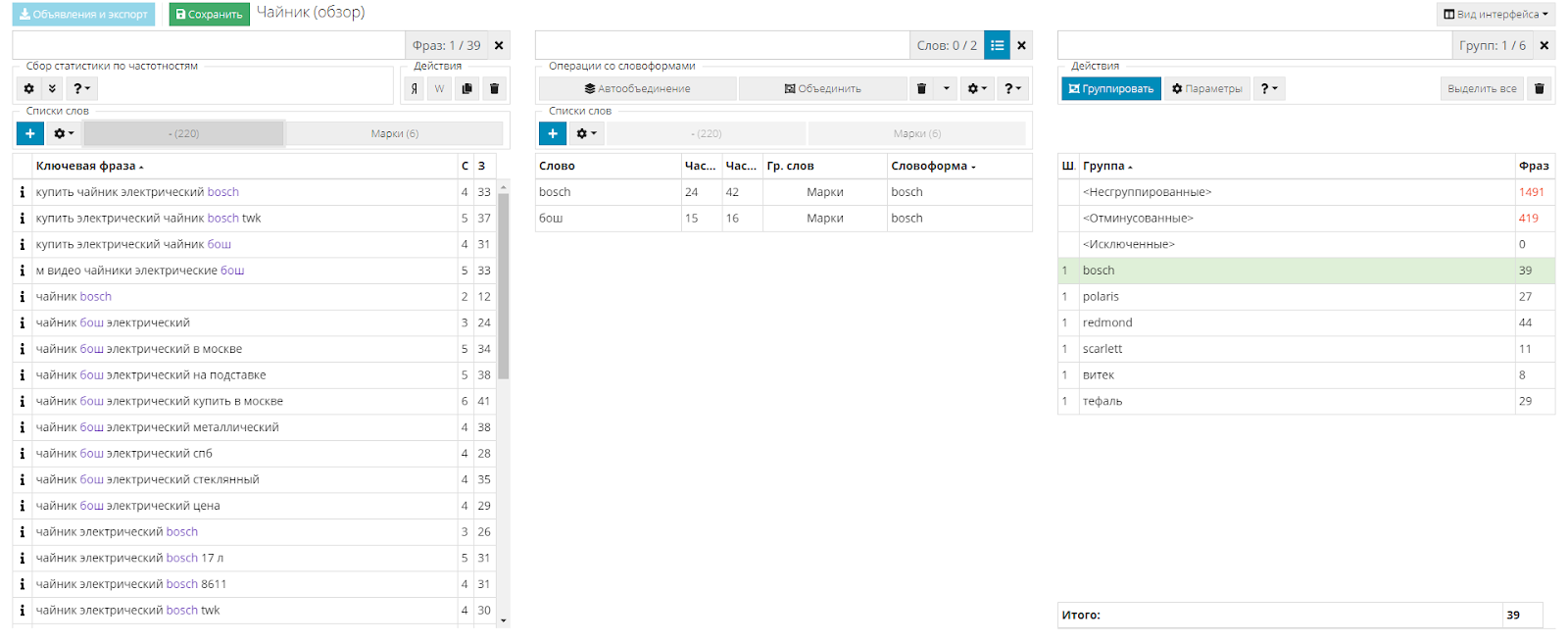
Проскроллив первый столбец, я вижу, что здесь присутствует ряд нецелевых запросов, таких как «Отзывы», «Фото» и так далее.
Моя задача - отправить эти слова в минус-список. Для этого над первой таблицей я активирую список с названием «-» и сейчас начну добавлять минус-слова.
Прошу обратить ваше внимание на то, что когда мы разбирали активацию списков, у нас был всего один, а теперь уже несколько. Теперь вы имеете возможность переключаться между списками и активировать тот, в который вы хотите добавить слово.
Также обратите внимание на то, что если во фразе присутствует слово из неактивного списка, оно выделяется фиолетовым и при наведении подскажет, в каком списке оно состоит.
Маленькая рекомендация: в левом верхнем углу есть кнопка «Сохранить», нажимайте ее периодически, чтобы перестраховаться на всякий случай.
Проделываем то же самое со всеми группами, после чего перегруппировываем и смотрим, что получилось.
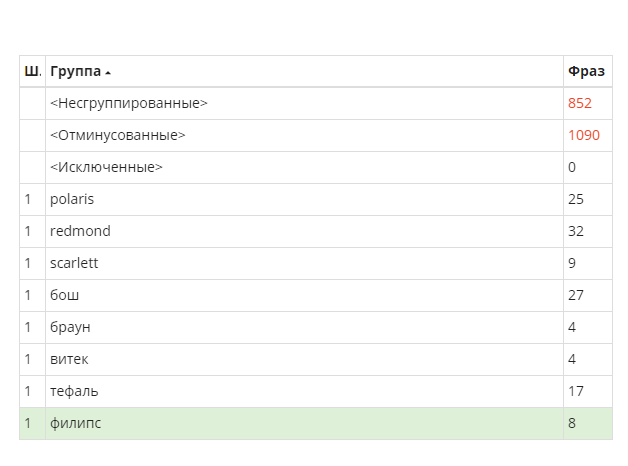
Как видим, количество мусорных фраз выросло, а группы избавились от нецелевых запросов.
Усложняем задачу. Так как при анализе групп мы встречали большое количество фраз с моделями, не выделить ли нам модели в отдельные списки и не сделать ли по ним группировки?
Не всегда это необходимо, но для примера я должен показать, как это работает, потому что у вас могут быть разные ситуации.
Создаем новый список с именем «Модели»:
- в третьей таблице выделяем группу;
- над первой таблицей активируем вновь созданный список;
- выделяем названия моделей и добавляем их в соответствующий список.
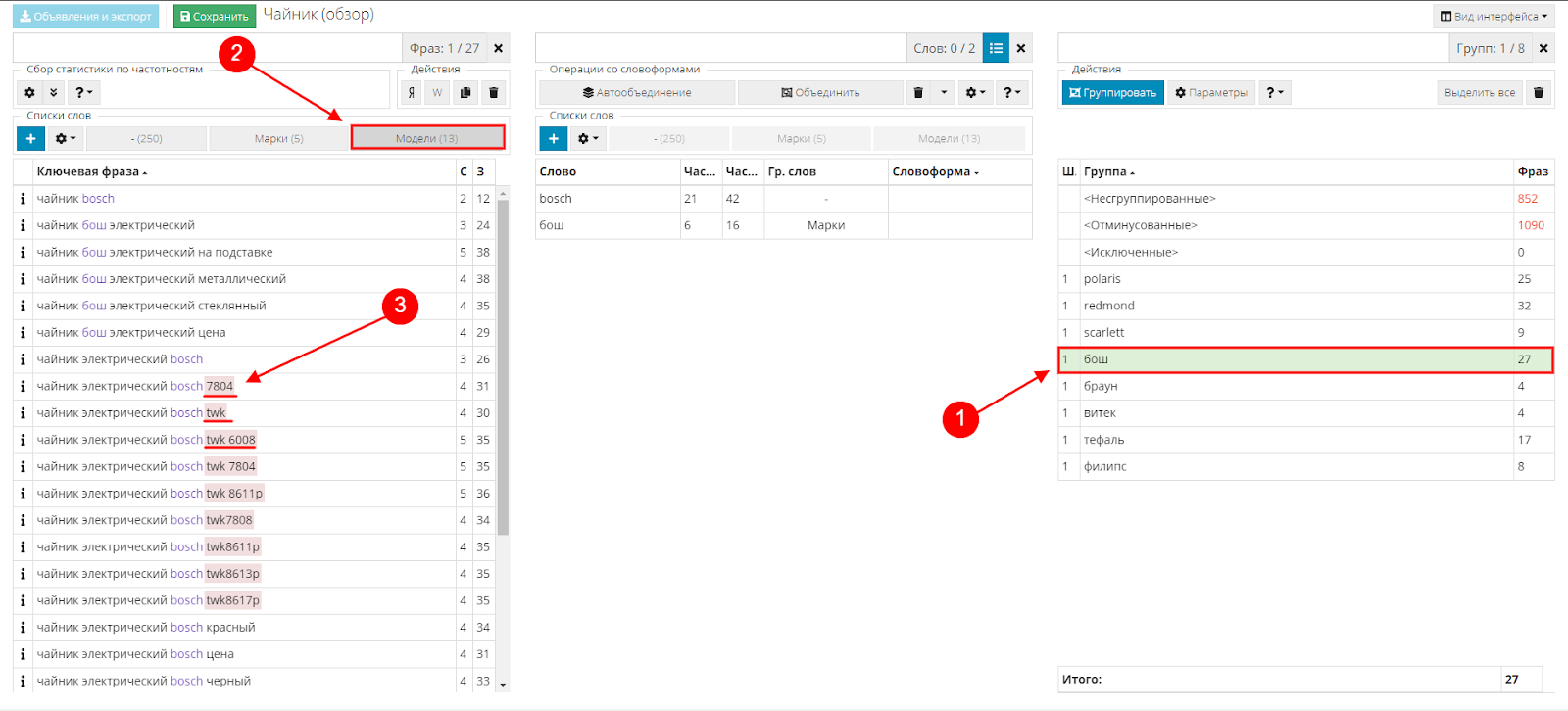
Проделываем это со всеми группами.
Обратите внимание, для ускорения процесса вы можете использовать вторую таблицу. Отсортируйте в ней слова в алфавитном порядке и выделяйте модели пачками, как показано на следующем скриншоте.
Только будьте внимательны, чтобы не добавить в список лишние слова.
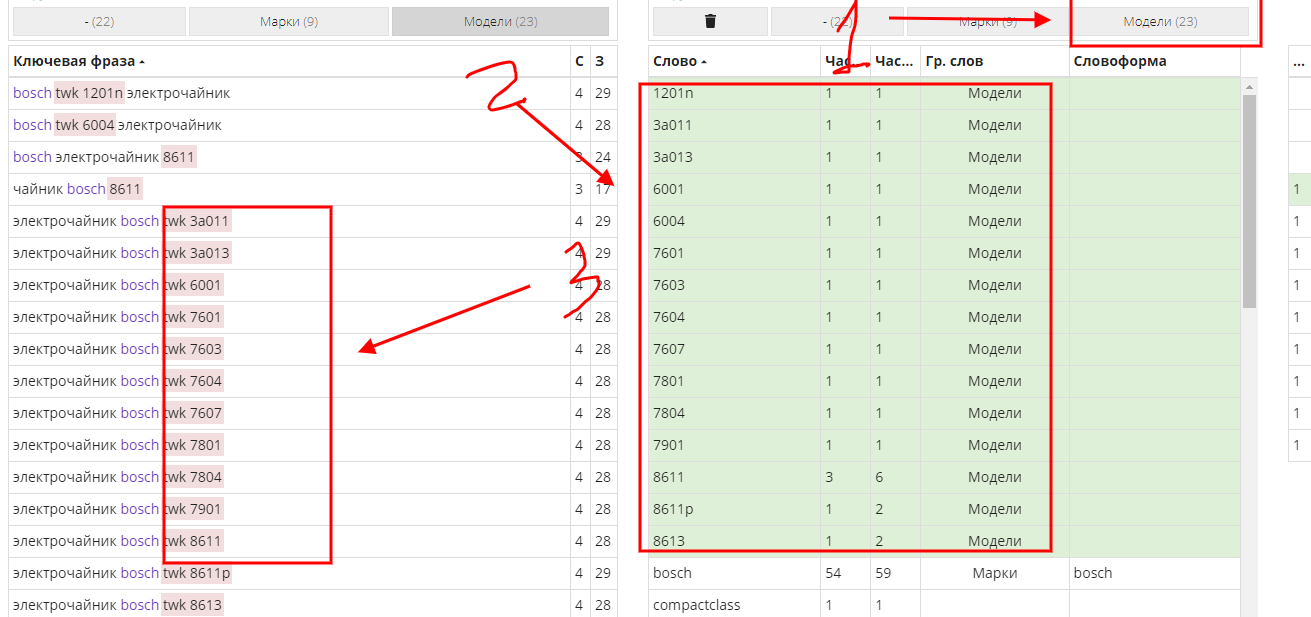
После проработки всех групп у меня получилось 196 слов в списке "Модели".
Но я мог что-то не заметить, поэтому при необходимости в процессе буду добавлять модели.
Что делаем дальше?
Давайте попробуем убрать фразы с моделями из группировок, чтобы посмотреть, какие запросы остались. Меньший объем данных всё же проще анализировать.
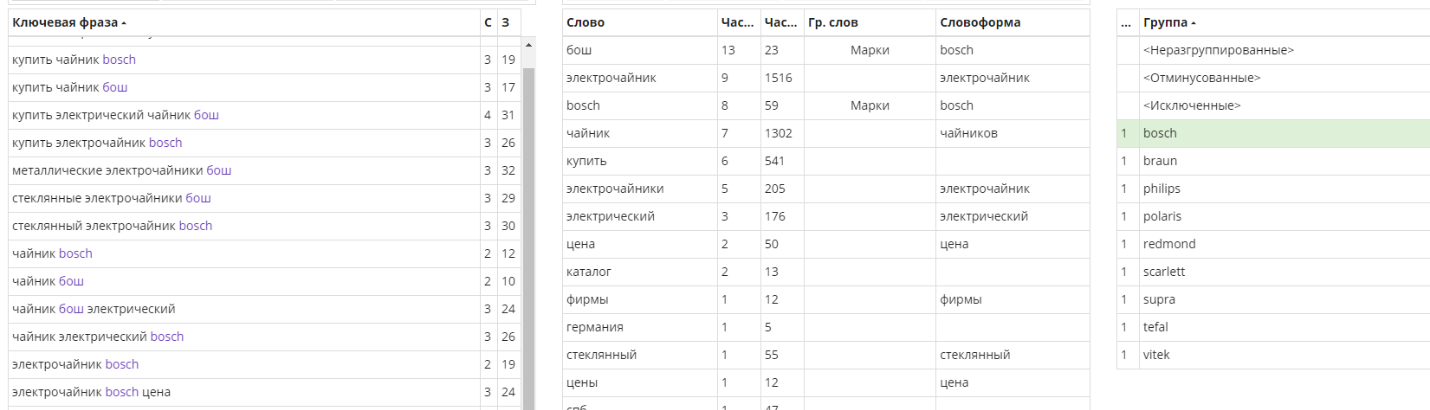
Для того чтобы это реализовать, мы временно назначим списку “Модели” статус “Минус-слова” и исключим их из основного списка.
В результате получились достаточно чистые группы.
В группах остались фразы, содержащие предмет (чайник), марку, транзакционные добавки и ГЕО-добавки.
Здесь уже каждый решает сам, как структурировать рекламную кампанию, стоит ли выделять ГЕО, разделять предмет на подгруппы и т.д.
Я покажу, как это сделать, а вы уже решайте сами.
Уточняем группировку. Делим группы на подгруппы
Задача - разделить существующие группы на подгруппы, для того чтобы сделать еще более релевантные объявления.
Для этого создадим еще один список, назовем его «+» и добавим в него слово «чайник».
Затем в настройках группировки добавим вновь созданный список и назначим ему статус «Группообразующий: несколько слов», жмем "применить и группировать".
Смотрим, что получилось.
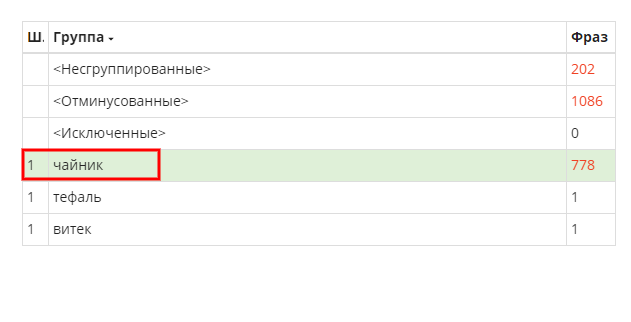
Получилось совсем не то, чего хотелось((
Мы ожидали, что получатся группы, содержащие слова из «+» списка и «модели», а получились только из «+», при этом сгруппировались все фразы из не сгруппированного, которые не содержат в себе названия марок.
Почему так произошло?
Так произошло, потому что система по умолчанию старается сделать максимально плотные группы, а так как мы не задавали никаких ограничений, и слово "Чайник" содержалось во всем семантическом ядре, UTA на этой основе создала максимально плотную группу.
Теперь давайте разберемся, как сделать, чтобы у нас получилась группа, содержащая в себе слова из списков «+» и «модели».
Переходим в настройки и повторяем за мной.
В поле «Число списков» ставим значение от 2-х, тем самым даем команду системе - при группировке обязательно учитывать только те фразы, в которых содержится слово из двух списков «+» и «Марки», так как они являются группообразующими.
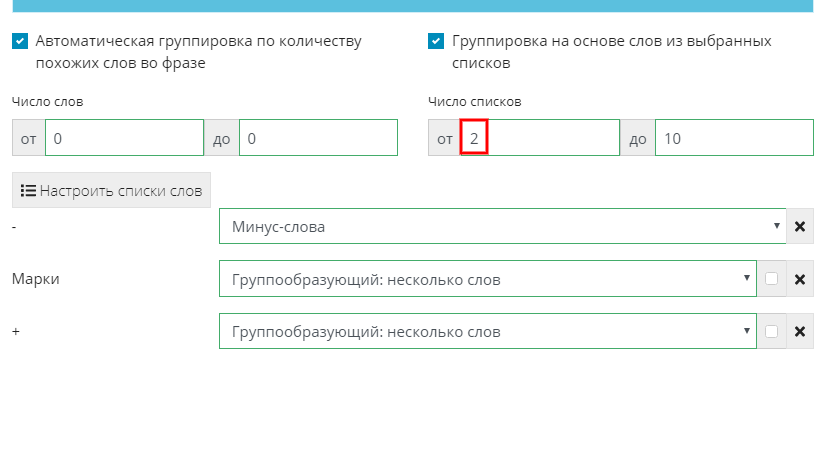
Группируем и смотрим, что получилось.
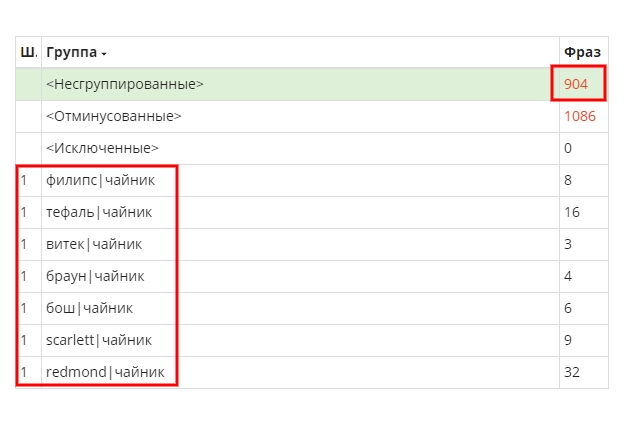
В итоге число фраз в неразгруппированных изменилось. Получается, система отсеяла фразы, не содержащие слова из списков, и создала максимально плотные группы.
Но нас это не устраивает, мы бы хотели, чтобы группы были более релевантными и состояли из заданных списков.
Для этого в настройках у нужных списков ставим галочку. Тем самым даем команду системе при группировке принудительно учитывать слова, содержащиеся в том или ином списке.
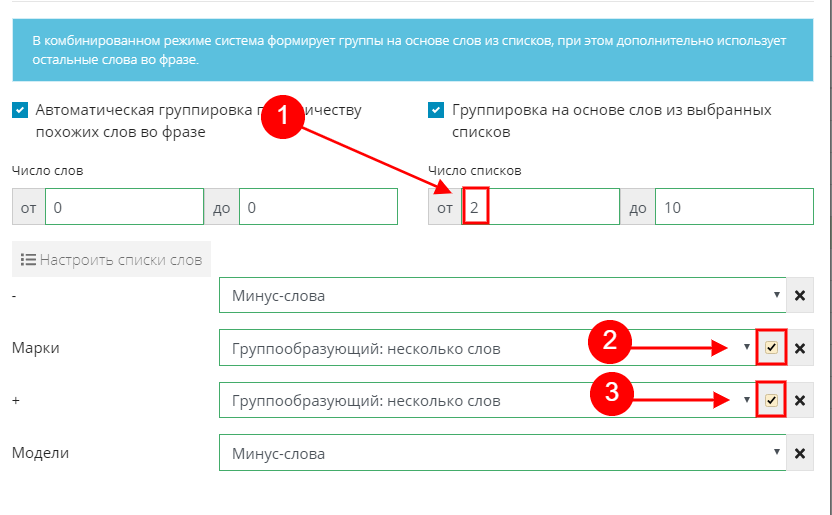
Применяем настройки, жмем "Группировать" и смотрим, что получилось.

Как видим, все удачно получилось, система сделала то, что нам было нужно - получились группы, сформированные на основе двух списков.
Подведем итоги и создадим объявления
Мы практически выполнили условия одной из задач.
Напоминаю, что было необходимо создать группы объявлений, имеющихся в наличии товаров, запросы типа «Чайник +марка/модель».
Для полного её выполнения необходимо вернуть модели из минусов и создать релевантные объявления.
Сейчас мы быстренько это проделаем, и попутно я покажу еще один лайфхак.
Идем в настройки, изменяем свойства списка модели на «Группообразующий: несколько слов». Так как у нас теперь три группообразующих списка, меняем настройки в числе списков на 3.
Но при этом не ставим галочку рядом со списком "модели". Посмотрим, что получится.
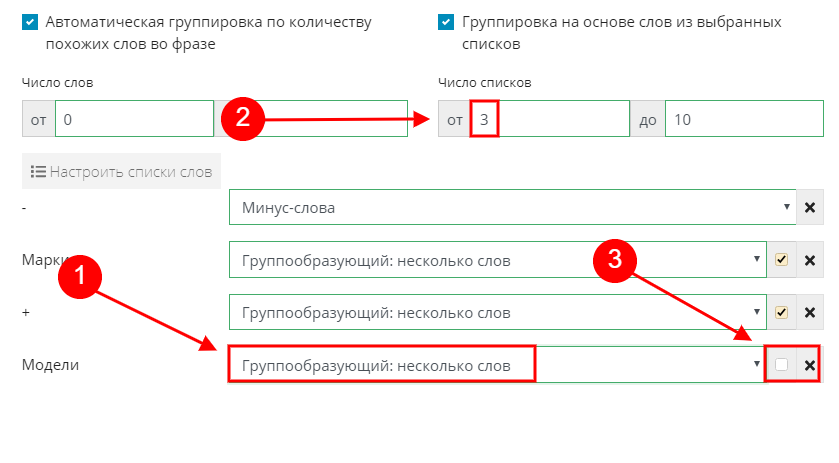
Применяем настройки и жмем "Группировать".
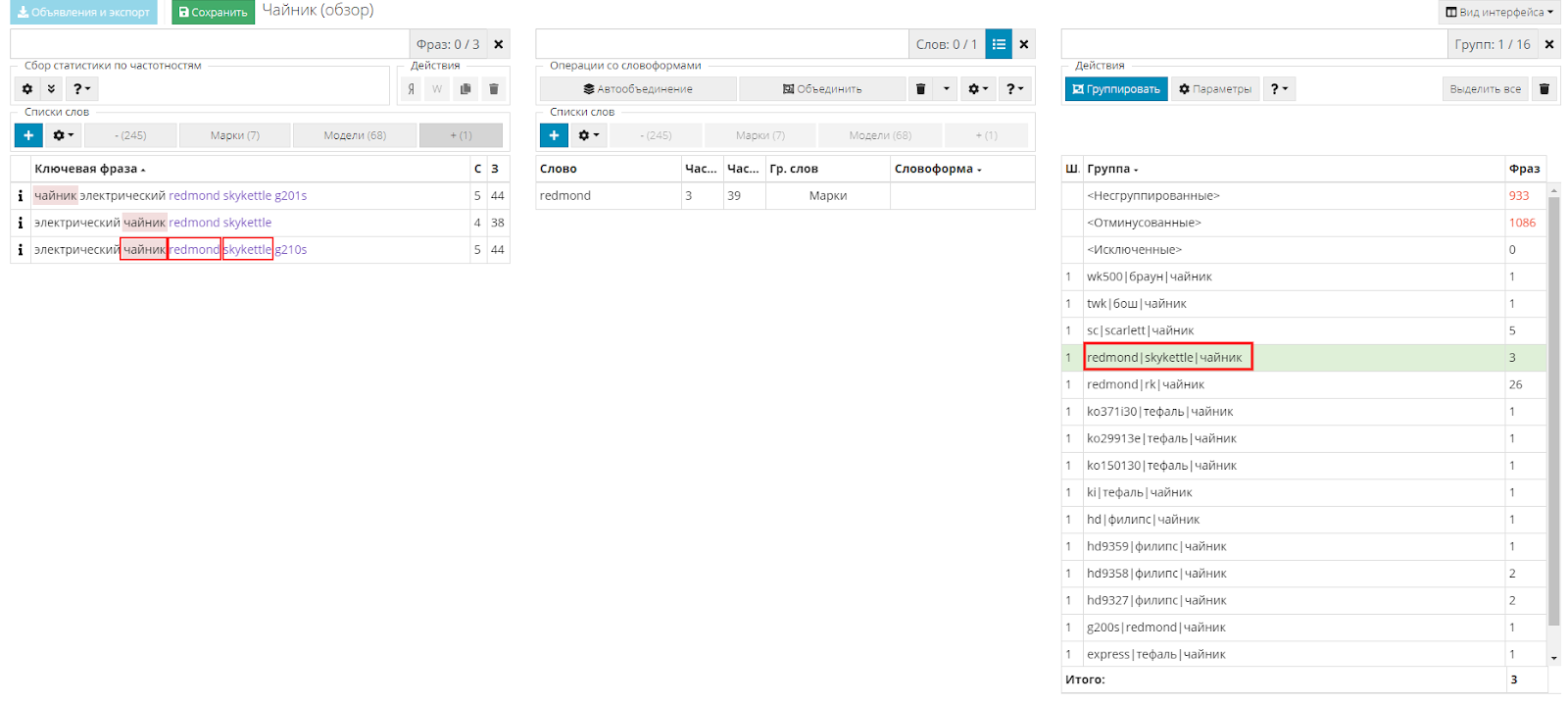
UTA сформировала группы на основе двух списков, отмеченных галочкой, при этом учла третий список, в котором содержатся марки.
В результате (так как в настройках задано отфильтровать только те фразы, в которых содержатся слова из трех списков) у нас остались очень точные запросы, т.е. «Предмет+Марка+модель», а фразы типа «Предмет+Марка» ушли в неразгруппированные.
Решить ситуацию можно двумя способами, первый самый простой.
В настройках группировок удалить список «Модели» и изменить число списков на меньшее значение (2).
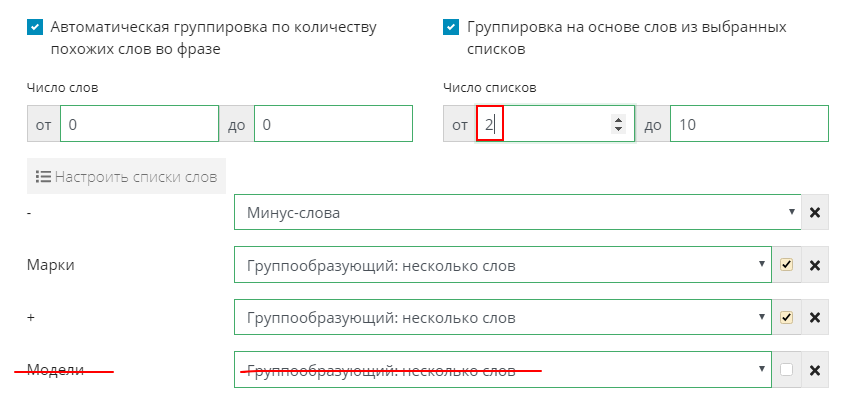
В этом случае получатся группы, содержащие все необходимые ключевые фразы - и с моделями, и без.
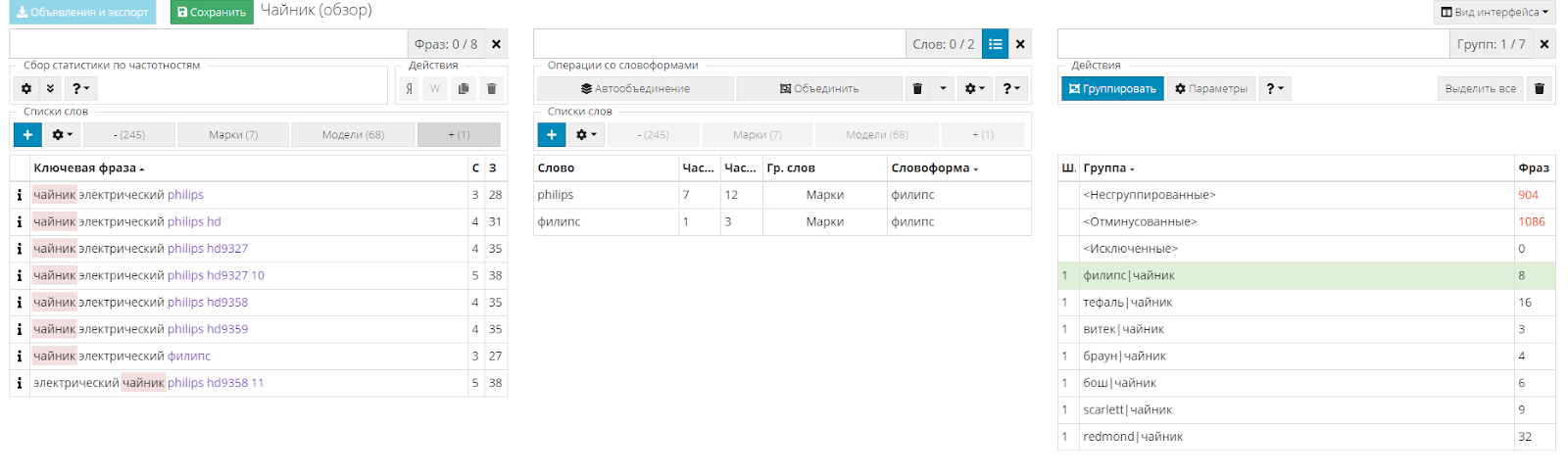
Но что делать, если необходимо разделить на отдельные кампании фразы, содержащее только марки и фразы, содержащие марки и модели.
Разберемся что такое "Шаги группировки"
Для этого есть простое решение, главное - понять смысл.
Переходим в настройки группировок. В левом углу всплывающего окна находим «Шаг 1» и жмем иконку "копировать". Система копирует настройки первого шага на второй.
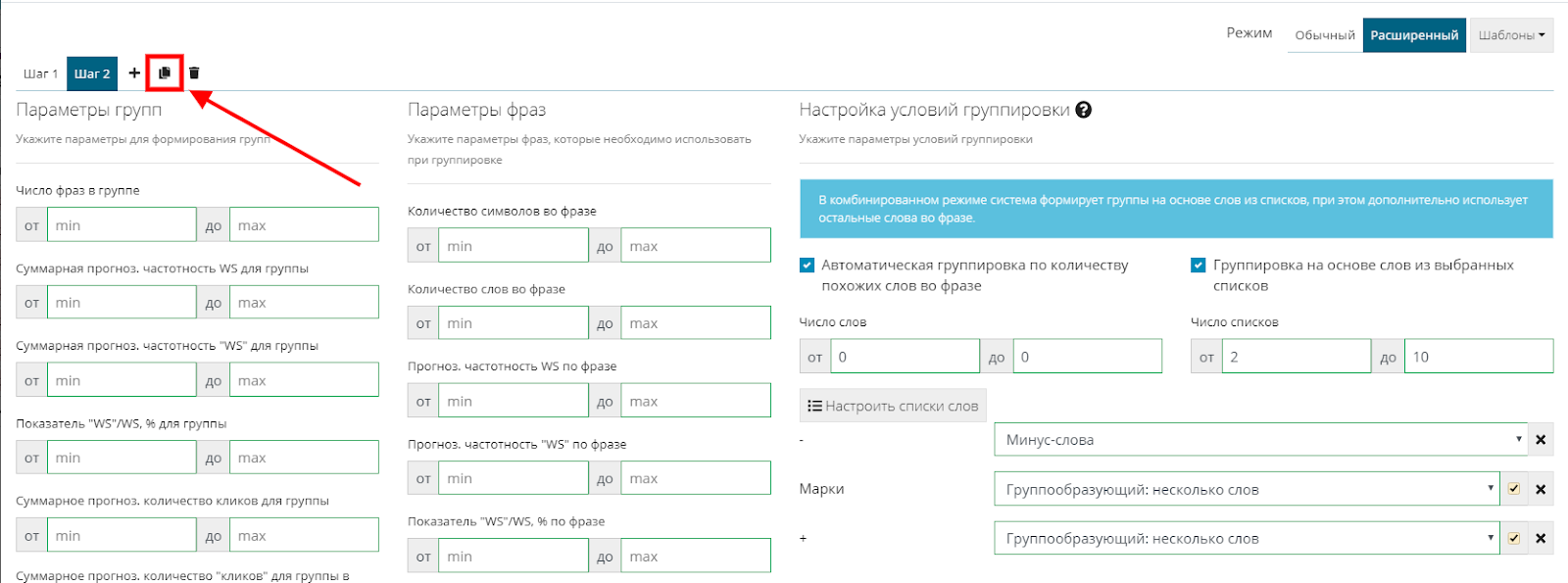
Теперь у вас активирована многошаговая группировка, позволяющая распределять семантическое ядро на разные кампании.
Опишу в двух словах, как это работает.
На каждом следующем шаге используются только те фразы, которые несгруппировались, были отминусованы или исключены на предыдущем шаге.
Благодаря этому можно делать разные комбинации и, обработав фразы на первом шаге, переходить к обработке на втором и использовать шаги как отдельные кампании.
Практикуемся в многошаговой группировке
Возвращаемся на первый шаг, жмем "Настроить списки" и добавляем модели. Так как мы хотим, чтобы на первом шаге остались только марки без моделей, назначаем списку «Модели» статус «минус-слова».
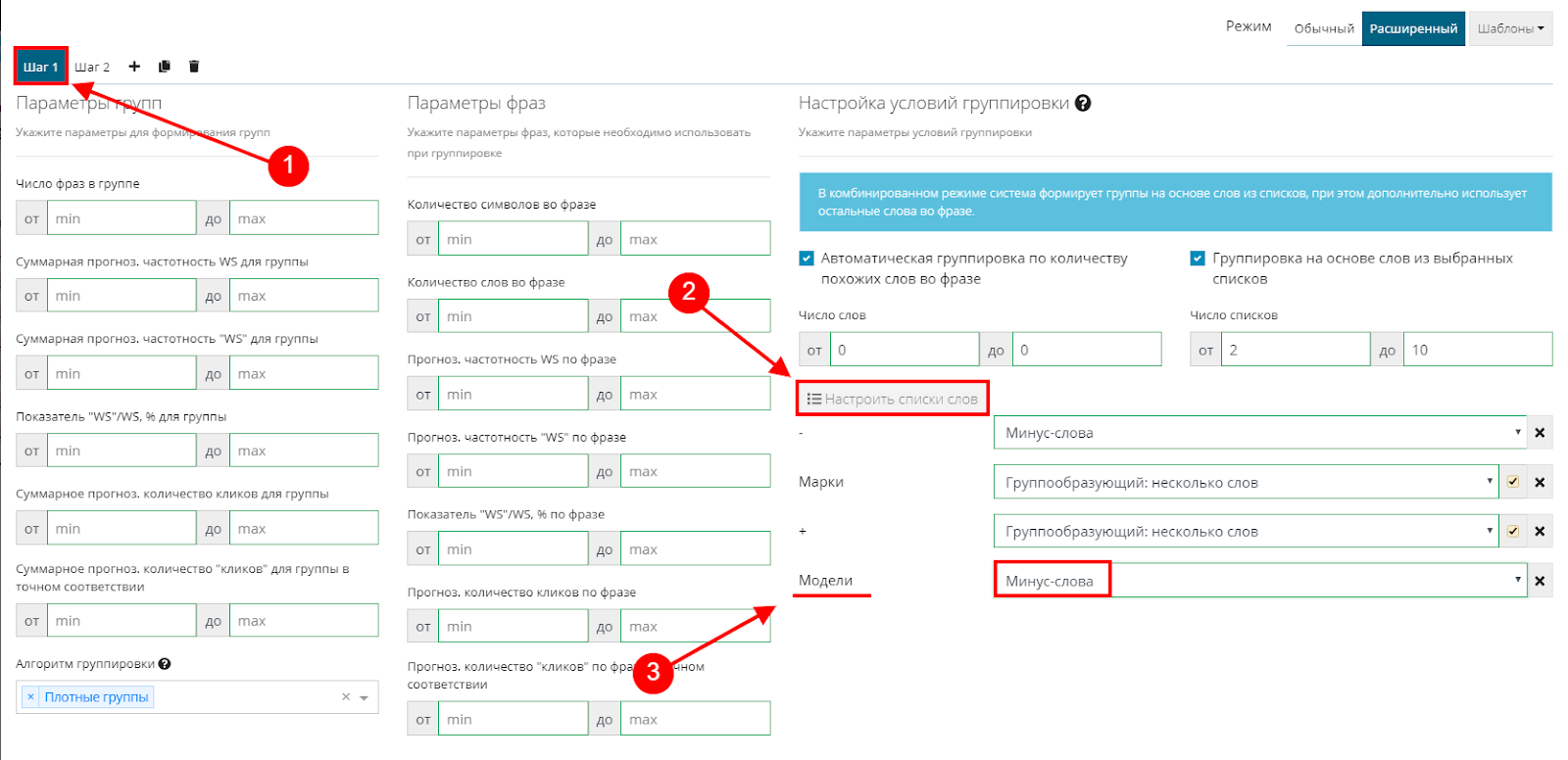
Затем переходим на второй шаг.
Также добавляем список «Модели», только в этом случае назначаем ему статус «Группообразующий: несколько слов» и не ставим галочку.
Далее в настройках числа списков повышаем значение до трех, так как нам необходимы группы, содержащие в себе слова из трех списков.
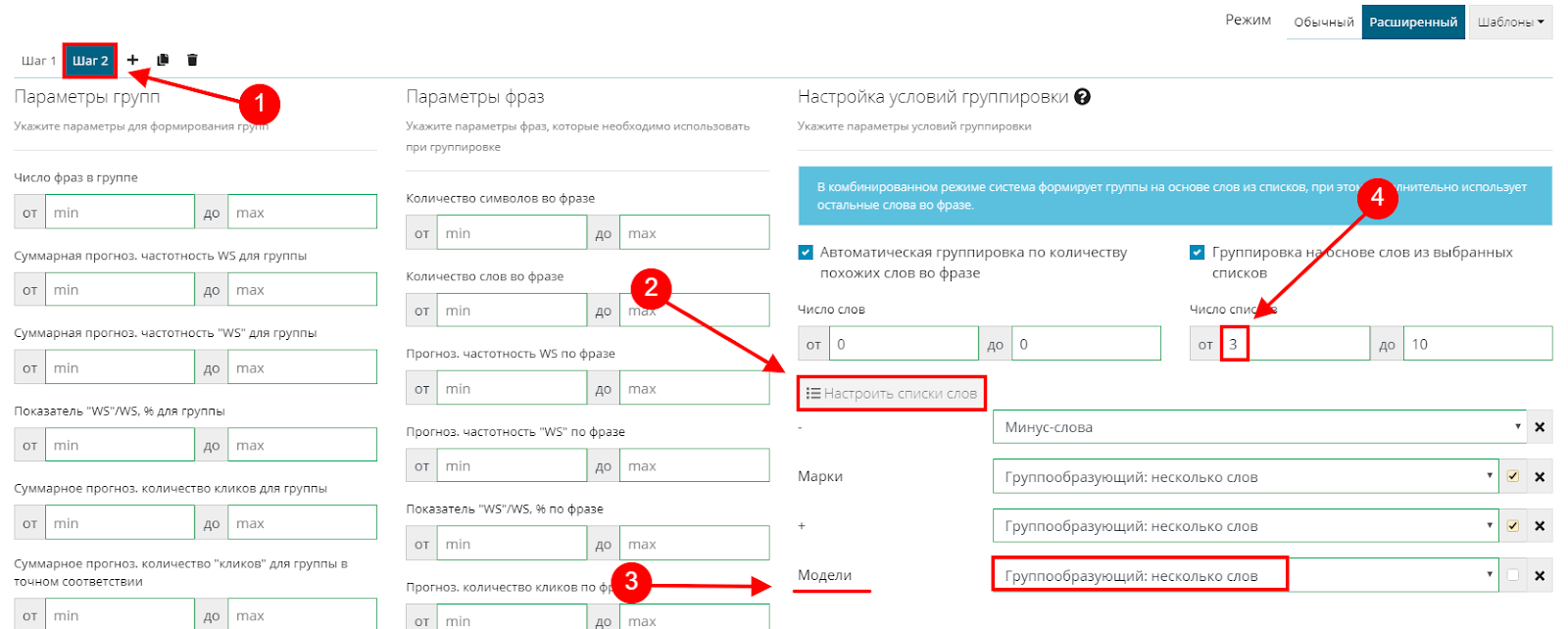
Применяем, группируем и смотрим, что получилось.
В третьей таблице сортируем по шагам столбец «…». При наведении на заголовок увидите подсказку.
После сортировки в верху списка оказывается второй шаг, выделяю первую группу и смотрю ее состав.
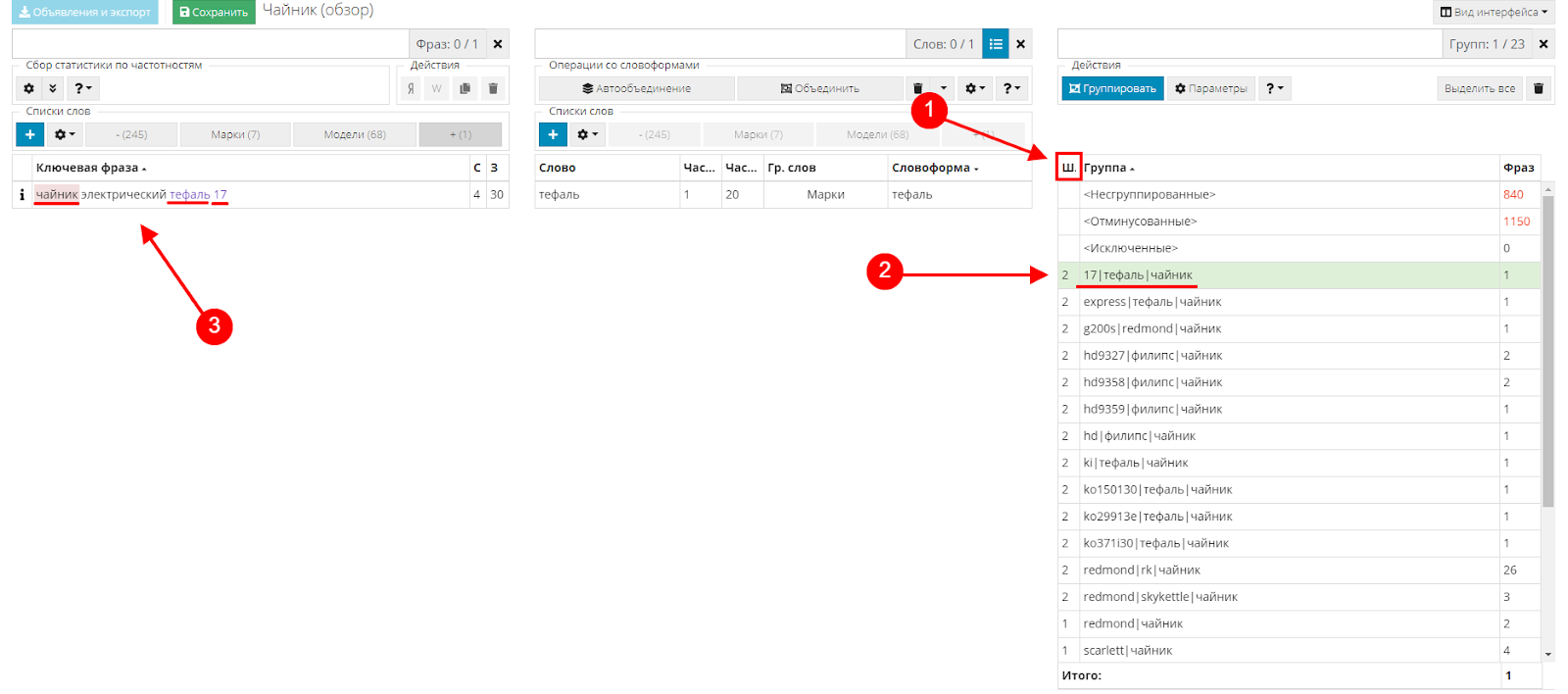
Как видно на скриншоте, на втором шаге у нас получились группы, содержащие в себе Марку+Модель+Предмет. Получилось именно так, как мы хотели.
Посмотрим, что на первом шаге.
В третьей таблице находим первый шаг и выделяем группу.
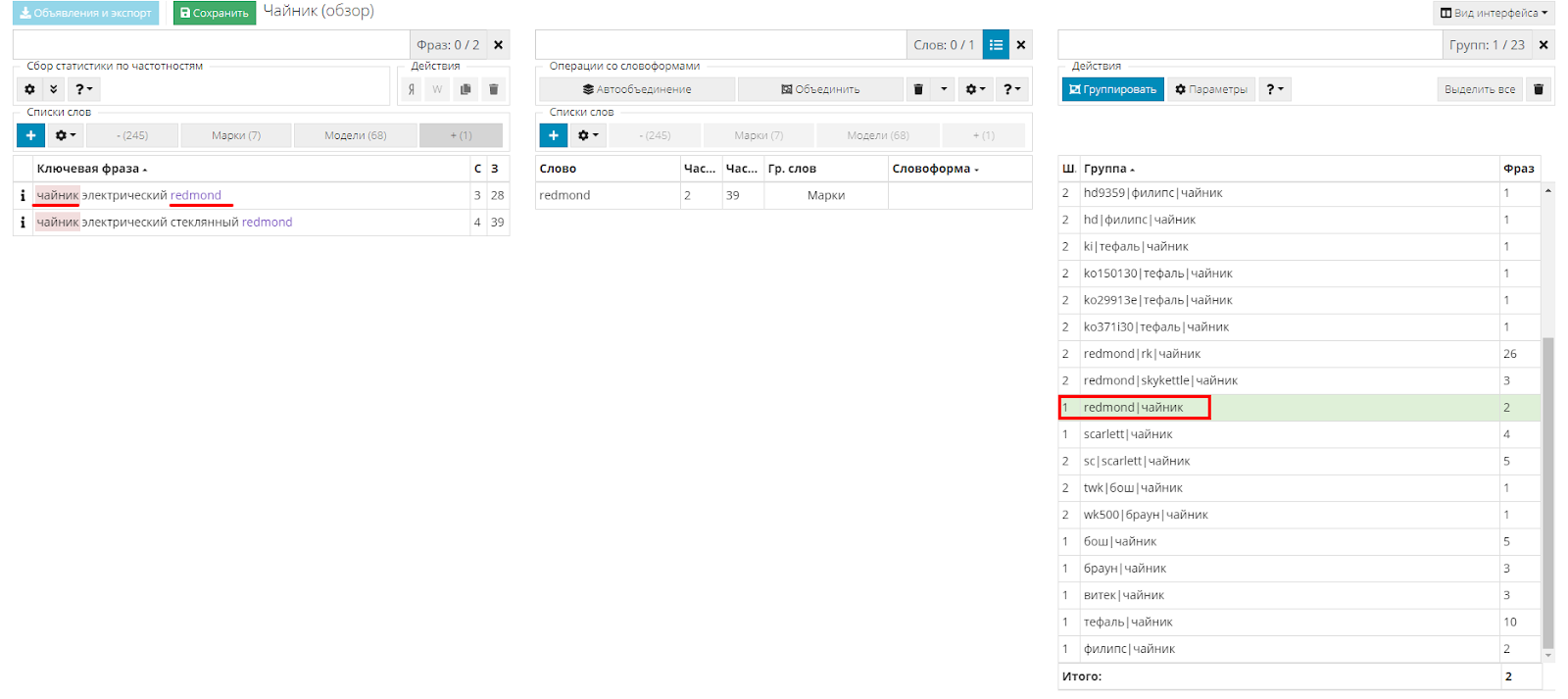
Все получилось, как мы и планировали.
Вам же рекомендую поиграться с настройками - на втором шаге попробовать выделить список «Модели» галочкой и посмотреть, что получится.
Подведем итоги: мы научились очищать семантическое ядро от мусора и выполнять многошаговые группировки. Теперь для завершения первой задачи нам необходимо создать релевантные объявления и сформировать CSV-файл для выгрузки в Яндекс.Директ.
Создаем релевантные объявления с помощью UTA-manager
Для создания релевантных объявлений система опирается на на статистику частотностей, для того чтобы подставить в заголовок максимально релевантную ключевую фразу. Поэтому нам необходимо собрать статистику для всех ключевых фраз в ядре.
Как собрать статистику по частотности ключевых фраз
О том как собирать статистику, я записал видеоролик, поэтому на этом не будем заострять внимание, если вы не знаете как это сделать - прошу проследовать по ссылке https://youtu.be/qSYwVgmPyj8.
В данном случае я буду собирать частотность по России.
Итак, у меня получатся 23 группы, разбитые на два шага.
Шаги буду использовать как кампании.
И осталось 840 несгруппированных запросов, с которыми еще предстоит поработать.
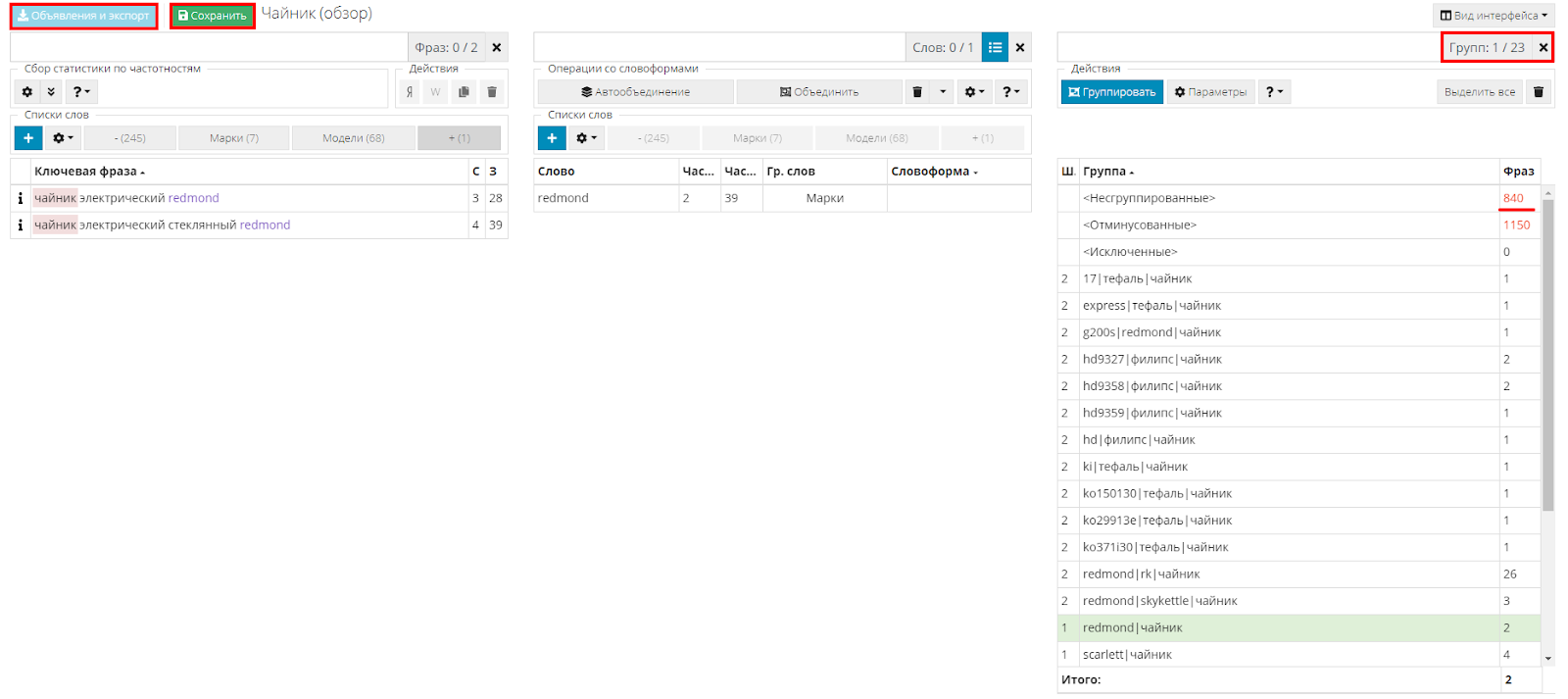
Фишка использования UTA-manager состоит в том, что буквально через 20-30 минут у вас уже будет готовая часть рекламной кампании, которую можно запускать и тестировать, пока прорабатывается остальное семантическое ядро.
Итак, статистика собралась.
Я жму "Объявления и экспорт" и перехожу к конструированию рекламных объявлений.
Названия марок пишем с заглавной буквы.
Первым делом выбираю списки слов, которые должны быть с заглавной буквы, в нашем случае это модели. Делаю это для того, чтобы сэкономить время в дальнейшем. Так как система в заголовок будет подставлять фразы, пусть эти фразы будут правильно написаны сразу.

Затем добавляю первое объявление.
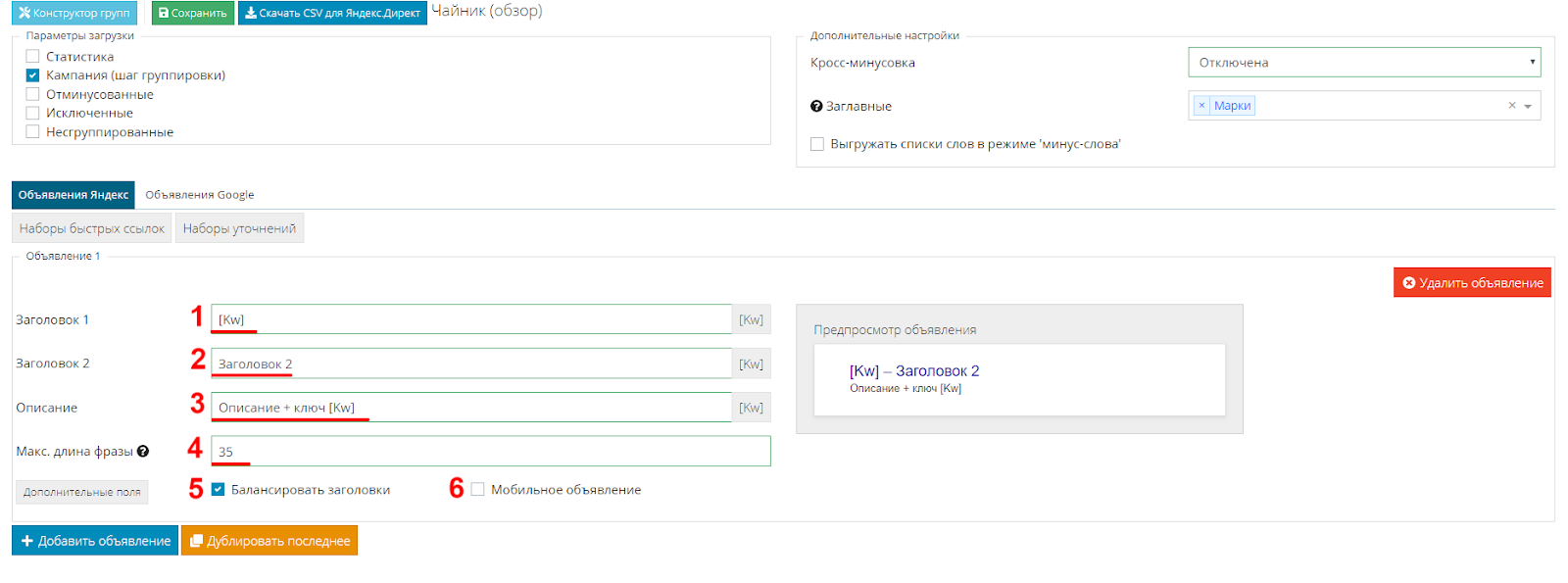
Добавляем релевантный запрос в заголовок
В поле "Заголовок" добавляю макрос, другими словами, это переменная, которая вместо себя подставит ключевую фразу.
В "Заголовок 2" пишу текст.
В описание ввожу текст и еще раз ставлю макрос, чтобы в описании тоже присутствовала ключевая фраза. Это не является рекомендацией, вы выполняете настройку в зависимости от ваших предпочтений, моя задача - показать возможности.
В строке «Макс. длина фразы» по умолчанию стоит значение 35, это означает, что приоритет будет отдаваться фразам, приближенным к этому значению, вы можете установить любое другое.
Перенос части из первого заголовка во второй
Следующая настройка «Балансировать заголовки» поможет распределить ключевую фразу на первый и второй заголовок в случае, если фраза по количеству символов не входит в первый.
Создание мобильных объявлений
«Мобильное объявление»: при активации этой настройки вы передадите информацию в Яндекс.Директ о том, что это объявление имеет приоритет для мобильных устройств. Сейчас ее ставить не будем.
Жмем кнопку "Скачать CSV" и смотрим, что получилось.
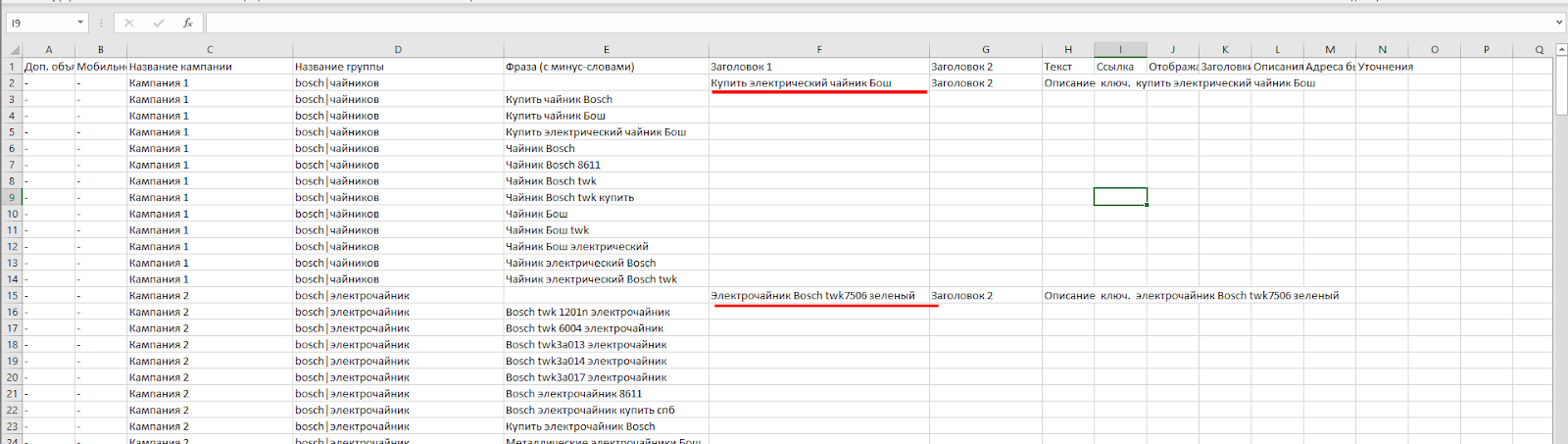
Как видим, система подготовила файл для выгрузки в Директ.Командер.
Пример полученного файла вы можете скачать здесь
Давайте разберем, что получилось. Все настройки на местах, система подставила ключевые фразы в заголовки, теперь ваша задача - проверить их и немного подкорректировать, если необходимо.
Как подготовить файл и загрузить его в Директ, рассмотрено в этом видео https://youtu.be/xioUX81Onqk.
Теперь не нужно выполнять настройки вручную. Используя конструктор Яндекс.Директ от UTA-manager, вам остается внести небольшие правки, и кампания готова.
Как добавить ссылки и дополнения в объявление
Но мы пойдем дальше. С помощью конструктора вы можете сразу добавить ссылки в объявления.
В правой части жмем на кнопку «Ссылка» и заполняем поля. При этом можно вводить ссылки сразу с UTM-метками.
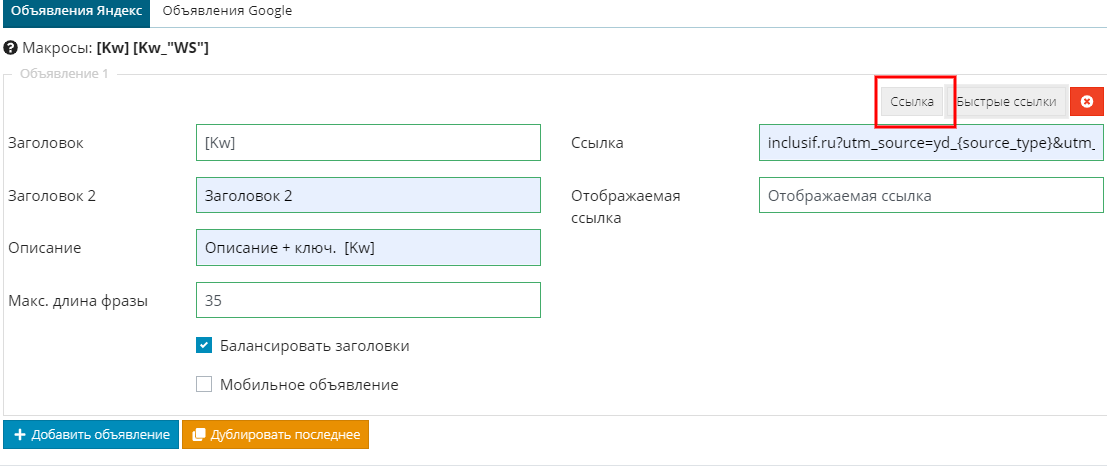
Для добавления быстрых ссылок активируйте соответствующую кнопку, после чего появятся настройки быстрых ссылок.

Добавляйте и заполните быстрые ссылки.
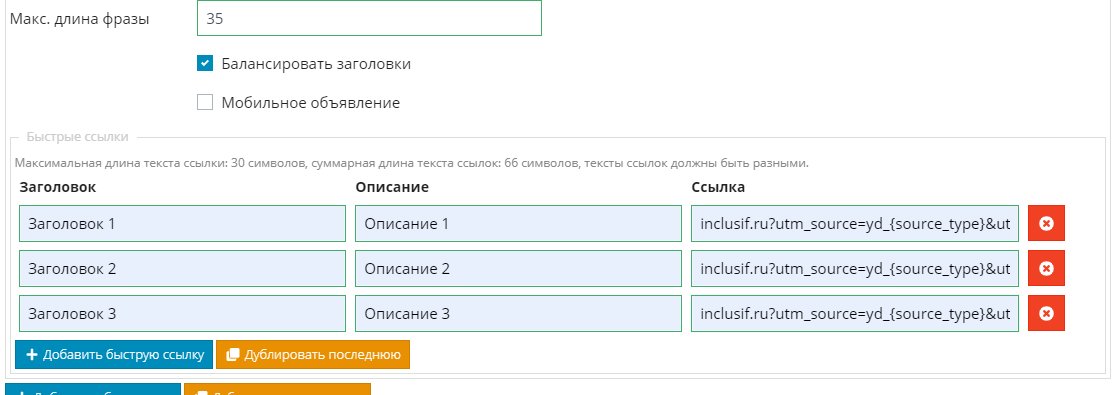
После чего можно нажимать "Скачать CSV".
Ссылка на получившийся файл здесь
Как подготовить файл и выгрузить его в Директ, рассмотрено в этом видео https://youtu.be/xioUX81Onqk.
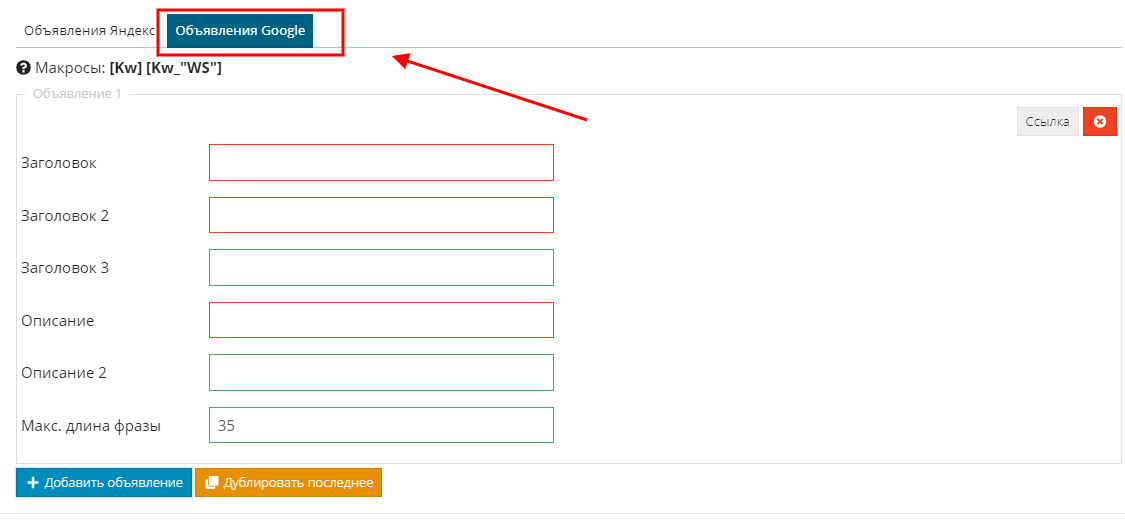
Обратите внимание: система дает возможность конструировать объявления в том числе и для Google рекламы.
Подведем итоги
Сегодня мы пошагово рассмотрели, как с помощью конструктора UTA-manager быстро создавать рекламные кампании.
В результате у нас получилось:
- собрать семантическое ядро;
- очистить ядро от мусора;
- составить списки минус-слов;
- сгруппировать ключевые слова по смыслу и по условиям;
- для каждой группы создать релевантные объявления;
- выгрузить кампанию в Яндекс.Директ.
С остальными задачами вы можете самостоятельно практиковаться и осваивать инструмент. Ссылки на материалы оставляю ниже.
- Регистрация в системе UTA-manager https://uta-manager.ru
- Список ключевых фраз используемых в примере
- Карта запросов
- Файл с группировкой
- Файл с группировкой и объявлениями
- Файл с группировкой, объявлениями + ссылки и дополнения
- Плейлист с часто задаваемыми вопросами по конструктору контекстной рекламы здесь.



Как настроить “Стратегии регулирования ставок”
- Базовые настройки для поисковых рекламных кампаний
- Базовые настройки для рекламы в сетях (РСЯ)
- Как работать с модификаторами
- Пример настройки условий модификатора
- Примеры формул для автоматизации ставок

Бид-менеджер - это часть функционала оптимизатора UTA-manager, этот инструмент называется “Стратегии регулирования ставок”, находится внутри рекламного кабинета на панели управления в разделе “Дополнительно”. Результаты и возможности оптимизатора
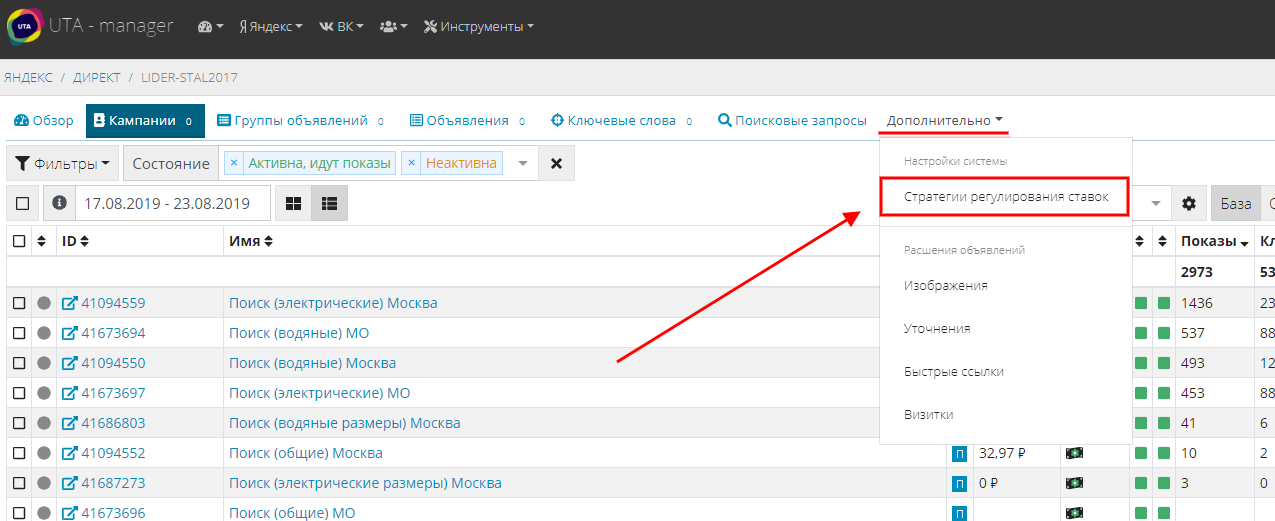
Перейдем к настройкам и создадим новую формулу. Для этого в левой части экрана нажмем на кнопку “+”:

Во всплывающем окне введем необходимые настройки:
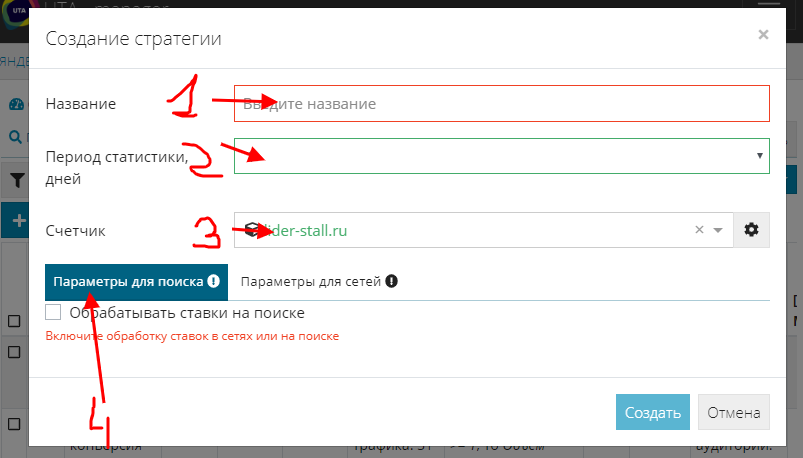
- Введите краткое название, по которому впоследствии можно будет понять суть формулы (например, ставка 150, или 75% ).
- Если вы будете использовать статистику Яндекс.Метрики для корректировки ставок, укажите, за какое кол-во дней система должна анализировать трафик.
- Выберите счетчик Яндекс.Метрики, для которого настраивается стратегия (счетчиков может быть несколько, поэтому необходимо выбрать, какой из них будет регулировать данную стратегию).
- Выберите тип рекламных площадок поиск/сети. Здесь уже на ваше усмотрение, можно сделать настройки для обоих типов площадок в одной формуле, можно разбить на несколько и применять каждую к соответствующей группе.
Рассмотрим возможности и различия обоих вариантов.
Стратегия для сетей отличается от поиска только в базовых настройках, модификаторы работают одинаково для обоих типов.
Базовые настройки для поисковых рекламных кампаний
Рассмотрим базовые настройки для поиска:
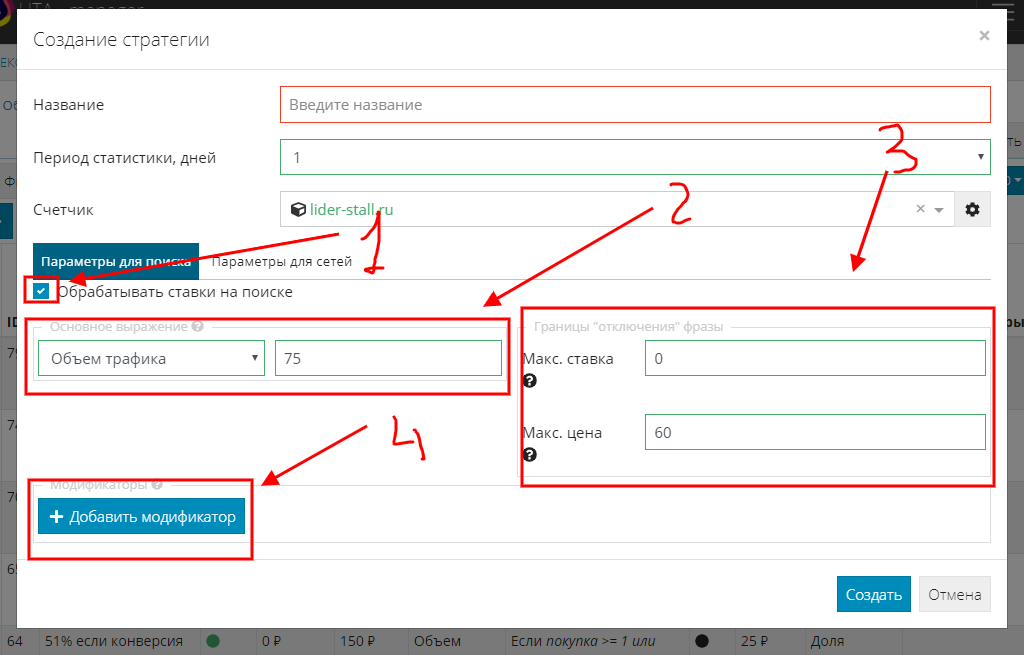
- Ставим галочку, после этого станут доступны все настройки для поиска.
- “Основное выражение” - базовое значение или, другими словами, формула по умолчанию. Будет применяться во всех случаях, если не выполнены условия модификаторов (что такое модификаторы, и как с ними работать рассмотрим ниже).
- “Границы отключения фразы” - ограничение по цене клика и ставке. Это предельные значения, модификатор не сможет их превысить.
- “Модификаторы” - настройки модификаторов.
Рядом с каждым полем есть справка “?”, где вы сможете найти подсказку и понять, как работает то или иное поле.
Например: вы хотите, чтобы система удерживала средний объем трафика в пределах 75%. Для этого в основном выражении выберите “Объем трафика” и установите необходимое значение. Все, теперь UTA будет удерживать цену автоматически, если конкуренция снижается - система опускает цену, если конкуренция станет выше - UTA поднимет цену, но не более установленных ограничений.
Можно задать фиксированную ставку или цену. Если вы выбираете эту формулу, то независимо от аукционов, UTA по умолчанию будет устанавливать фиксированное значение.
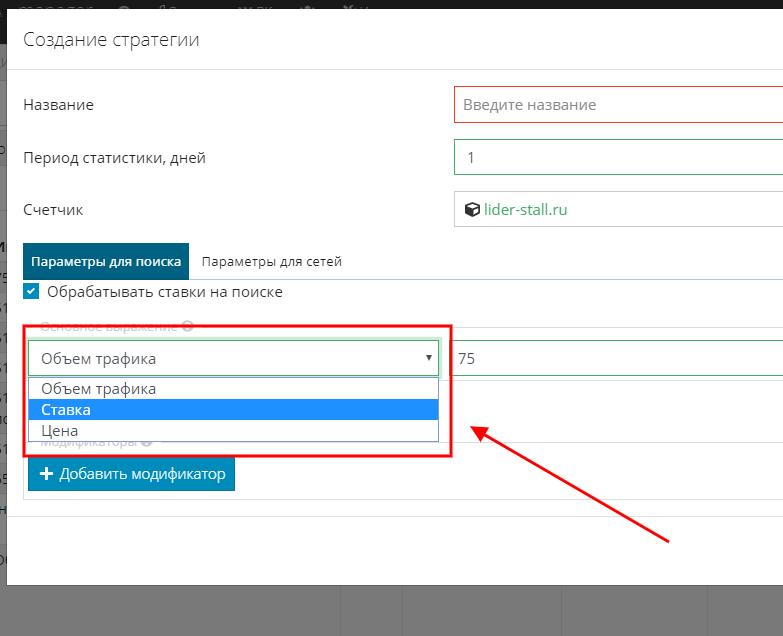
Использовать простые условия можно в связке с модификатором. Например, цена клика по умолчанию 5 руб., но если выполнено условие модификатора, система поставит заданную цену.
Базовые настройки для рекламы в сетях
Отличие от настроек на поиске следующие:
- нет цены клика, есть только ставка;
- если на поиске вы можете установить практически любой процент охвата, то для сетей их всего 3 (20,50,100);
- минимальная ставка 4 руб. для фраз, по которым нет прогноза статистики.
Рассмотрим на примере, как устанавливается ставка.
Предположим, что в основном выражении вы установили долю аудитории, равную 50%, а в границах отключения фразы поставили максимальную ставку 10 руб.:
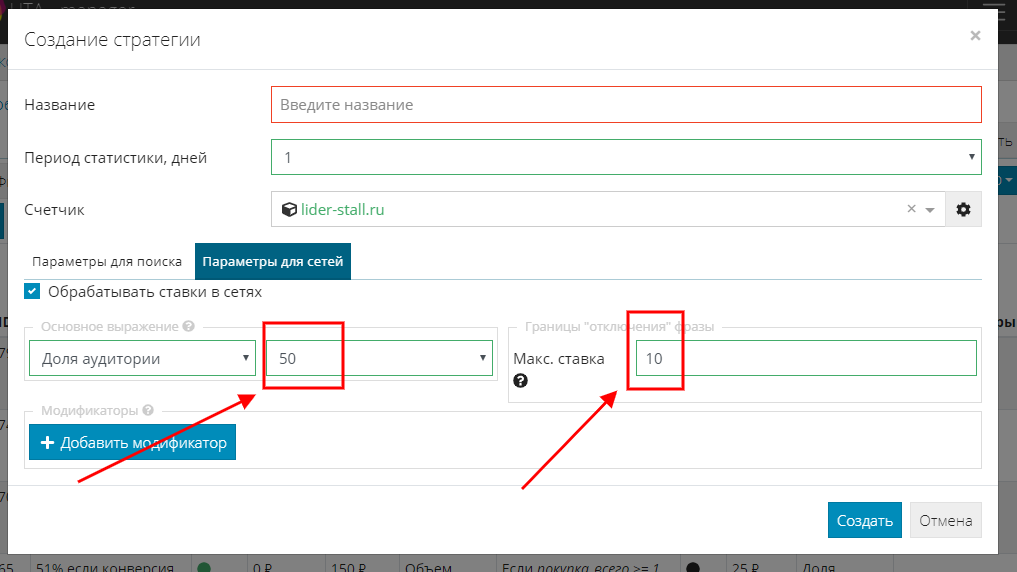
При таких настройках система постарается выполнить все условия. Но если для фразы у Яндекса не будет статистики, то в этом случае для таких фраз UTA применит минимальную ставку 4 руб., этого достаточно для показов по минимальной ставке, чтобы потихоньку набиралась статистика.
Если статистика есть и стоимость 50% охвата, например, 6 руб. - система снизит ставку до этих пределов, за счет чего вы сэкономите рекламный бюджет.
Если Яндекс попросит цену, превышающую заданное ограничение, и 50% трафика будет стоить, например, 20 руб., то в таком случае UTA-manager установит для фразы максимально возможное значение 10 руб.
Если вы хотите зафиксировать одинаковую ставку для всех фраз, в основном выражении выберите “Ставка” и установите значение:
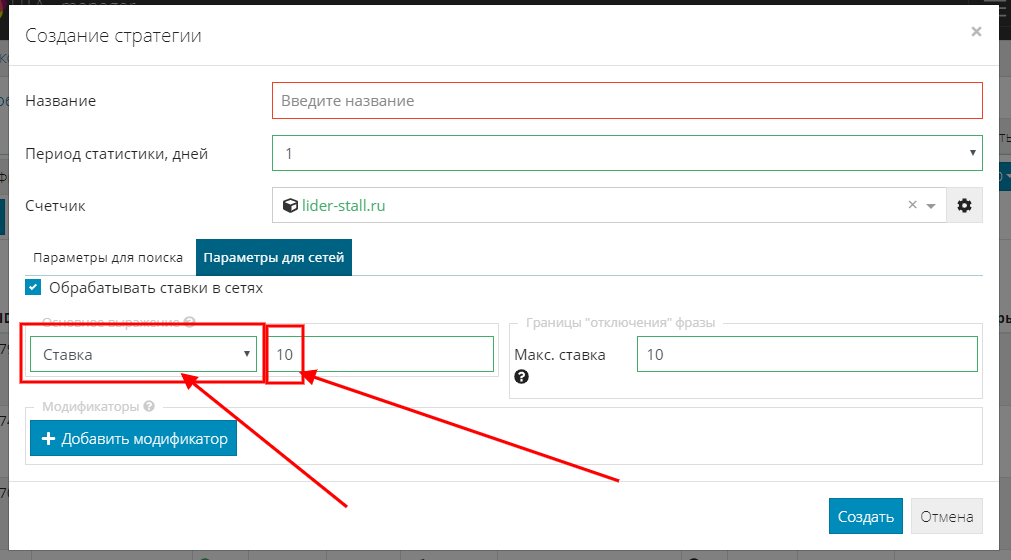
Как работать с модификаторами
Модификаторы - это гибкость. Модификатор ставки расширяет возможности основного выражения, позволяет задавать более гибкие условия для управления ставками.
Добавляем первый модификатор, для этого жмем кнопку “+ Добавить модификатор”:
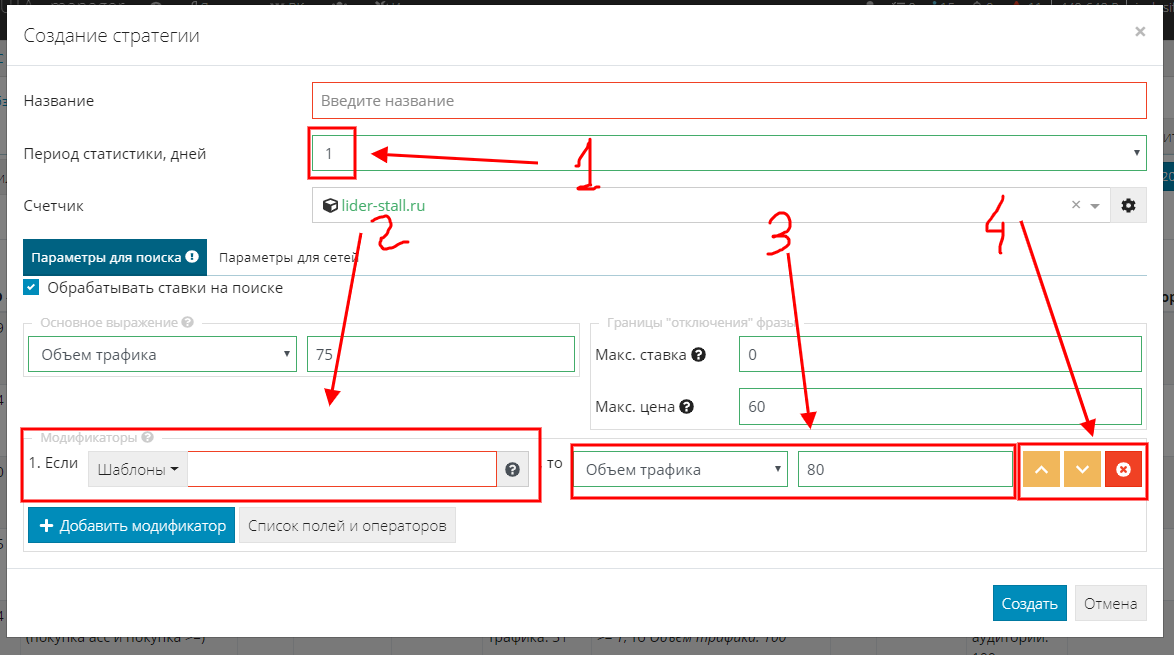
- Первый блок - выбираем кол-во дней, за которое система должна учитывать статистику Яндекс.Метрики в модификаторе.
- Второй блок - задаем основное условие.
- Третий блок - если условие выполнено, то система установит заданные значения.
- Четвертый блок - позволяет регулировать приоритет модификатора (в приоритете тот, который выше) или удалить модификатор.
Пример настройки модификатора и условий
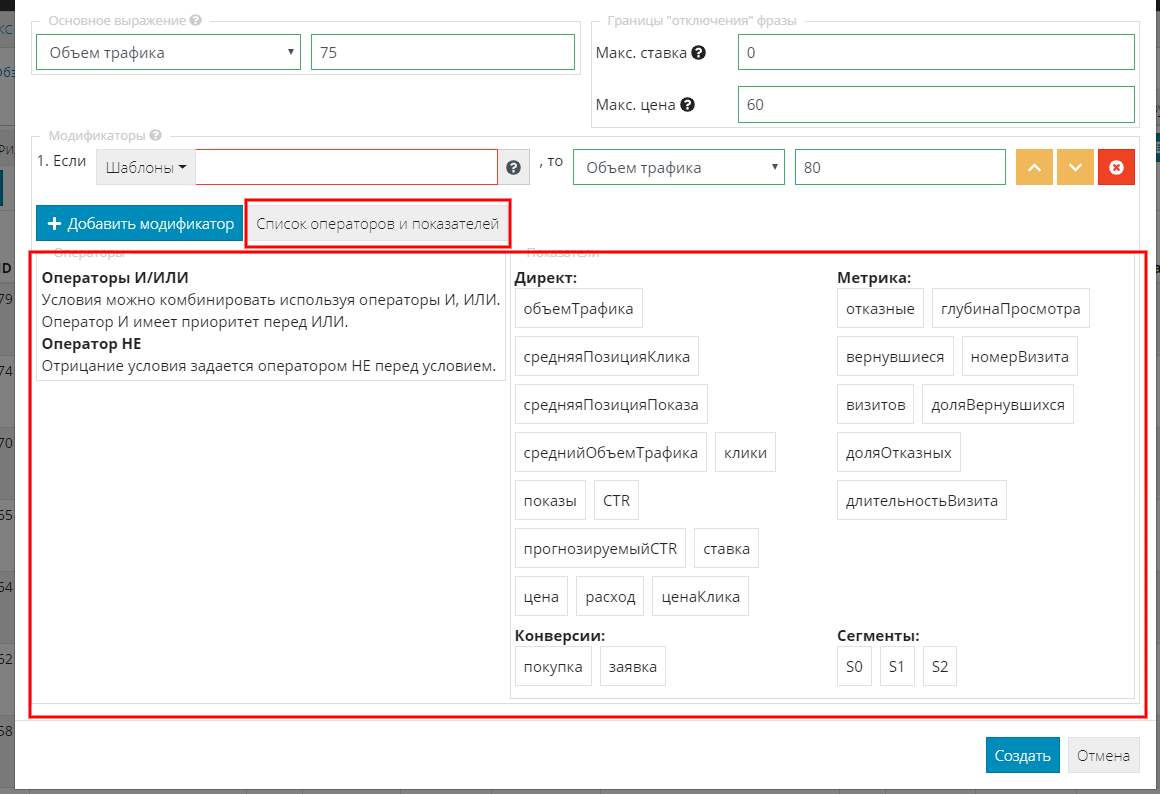
Модификатор поддерживает логические условия И/ИЛИ, также имеет возможность устанавливать отрицательные условия.
Модификатор поддерживает более 20-ти показателей, которые помогут настроить “идеальную” стратегию. Для того чтобы увидеть подсказки, нажмите кнопку “Список операторов и показателей”:
Создадим несколько модификаторов
Создадим два модификатора, которые будут регулировать условия показов.
Предположим, что мы хотим отключить фразы с низким CTR. Но в то же время не хотим допустить ошибку и исключить фразы, которые еще не набрали статистику.
Также мы хотим, чтобы фразы, по которым есть заявки, имели больший охват (так мы будем иметь возможность получать большее число заявок). А для фраз, по которым за последние 28 дней не было заявок, мы понизим охват с целью снижения рекламных бюджетов.
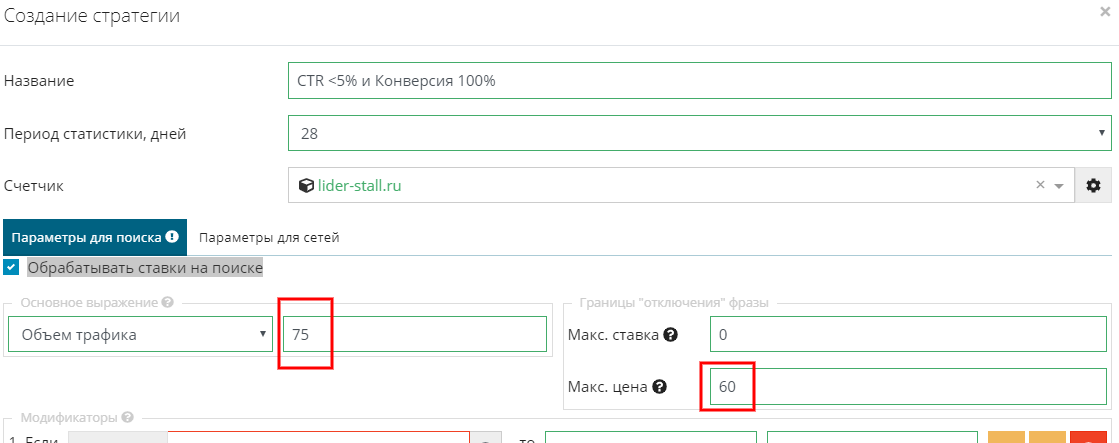
Для этого в поле “Период статистики, дней” установим значение “28”, это означает, что система будет опираться на данные за последние 28 дней:

Ставим галочку в пункте “Обрабатывать ставки на поиске”, так как создаем стратегию для поиска.
В поле “Основное выражение” ставим значение “Объем трафика = 75”, это означает, что по умолчанию для всех ключевых фраз будет установлена ставка за 75% объема трафика.
В полях “Границы отключения фраз” установим максимальную цену клика 60 руб.
Внимание!!! Если мы установим только значение цены, то UTA-manager автоматически для каждой фразы определит ставку, которая позволит получать клики по средней стоимости 60 руб.
Если необходимо, вы можете ограничить и ставку или установить ее пределы, а цены не устанавливать. Поступайте как вам привычнее, система предусматривает разные варианты.
Переходим к настройкам модификаторов. Начнем с модификатора, который регулирует ставки относительно показателей CTR.
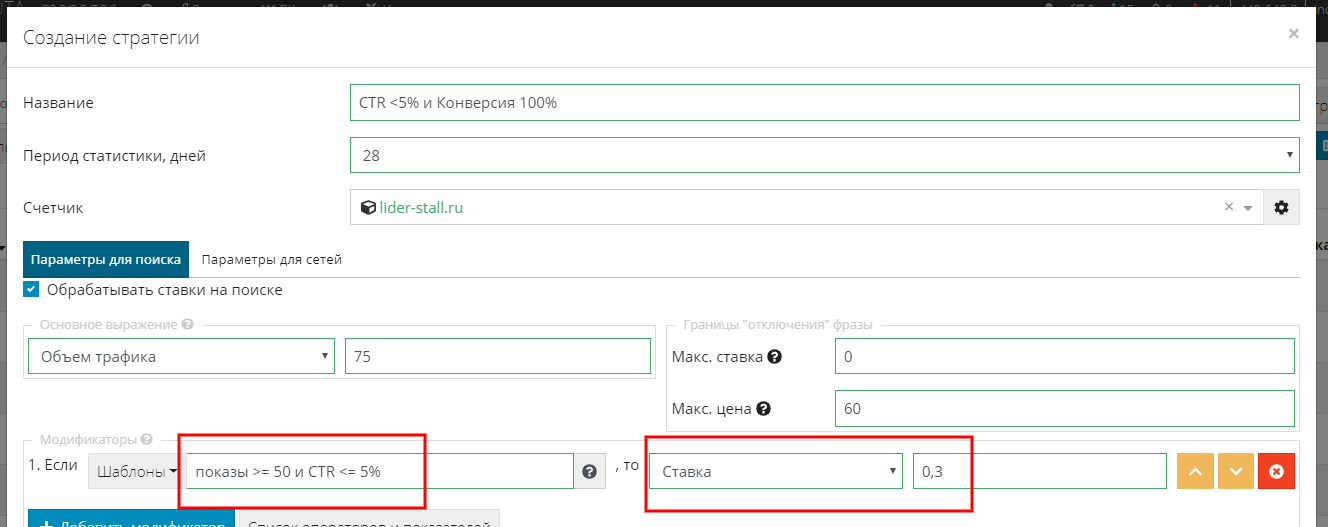
Как мы говорили ранее, чтобы не допустить ошибку и не исключить фразы, у которых малая статистика, мы не будем брать фразы, у которых кол-во показов ниже 50 за последние 28 дней.
Для этого выбираем из выпадающего окна “показы” и устанавливаем для них значение >= 50, добавляем логический оператор “И” и добавляем желаемое значение CTR, ниже которого фразы будут отключаться, в нашем случае путь это будет 5%.
Устанавливаем значение ставки "0,3", т.е. если фраза будет иметь более 50 показов и при этом CTR у нее будет 5% или ниже, то система установит ставку, равную 0,3 руб., что означает полную остановку показов:
Создаем второй модификатор по той же схеме.
Здесь немного посложнее, помните, когда мы настраивали конверсии, мы настроили два типа - заявка и покупка.
Соответственно, если мы хотим учитывать обе, то будем использовать логическое условие “ИЛИ”. Но есть еще один нюанс!
Система может учитывать ассоциированные конверсии, поэтому кол-во показателей у нас кратно увеличивается:
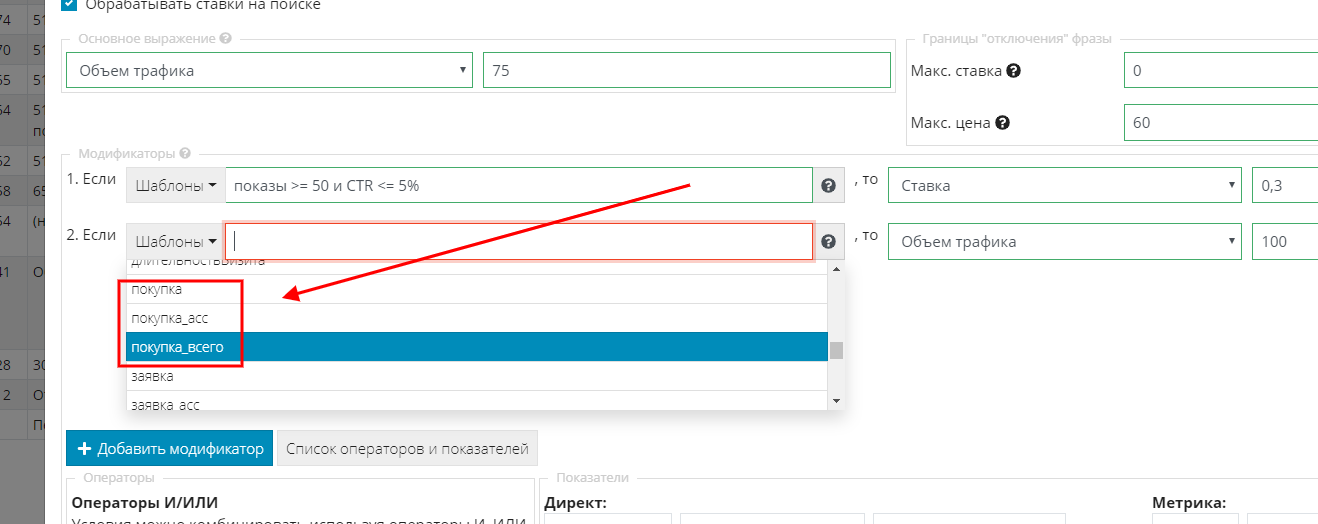
Здесь на ваш выбор: в зависимости от ваших задач вы можете использовать тот или иной показатель. В нашем случае я буду использовать следующее условие: “покупка_всего >= 1 или заявка_всего >= 1”.
Вот что получилось:
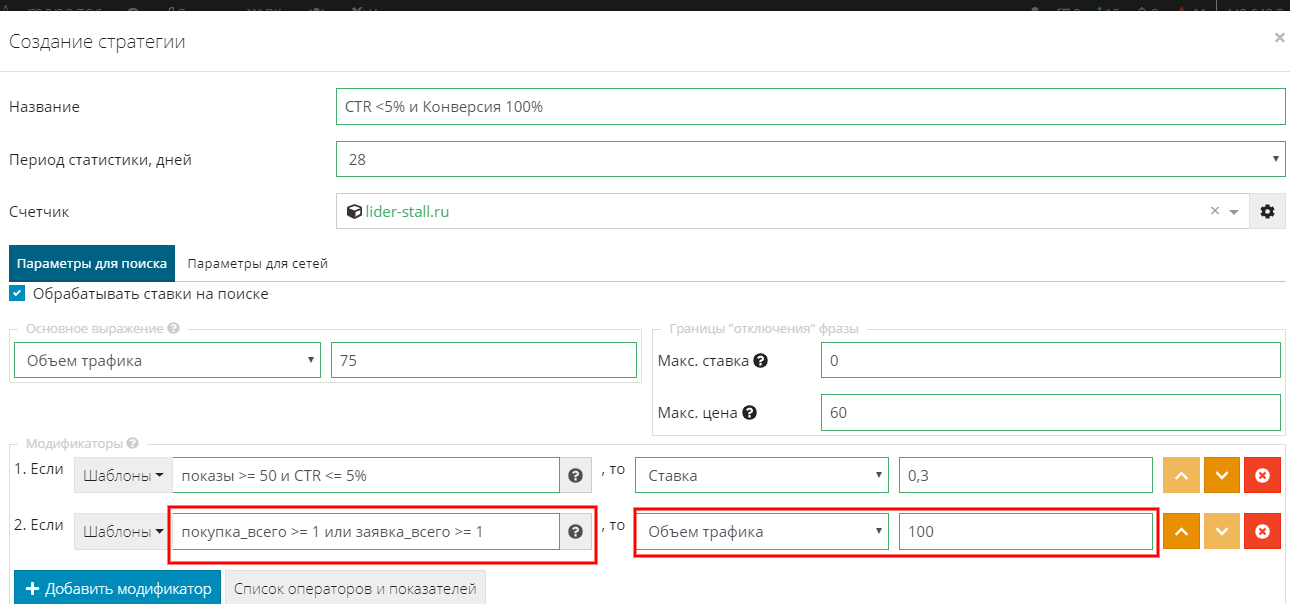
Получается, если у фразы было более одной заявки или покупки, то система установит ставку, равную 100% объема трафика.
Можно пойти еще дальше и установить третий модификатор для фраз, которые за последние 28 дней не принесли конверсии, но при этом получили более 100 кликов. Для таких фраз можно снизить объем трафика до 35% и существенно сэкономить рекламный бюджет.
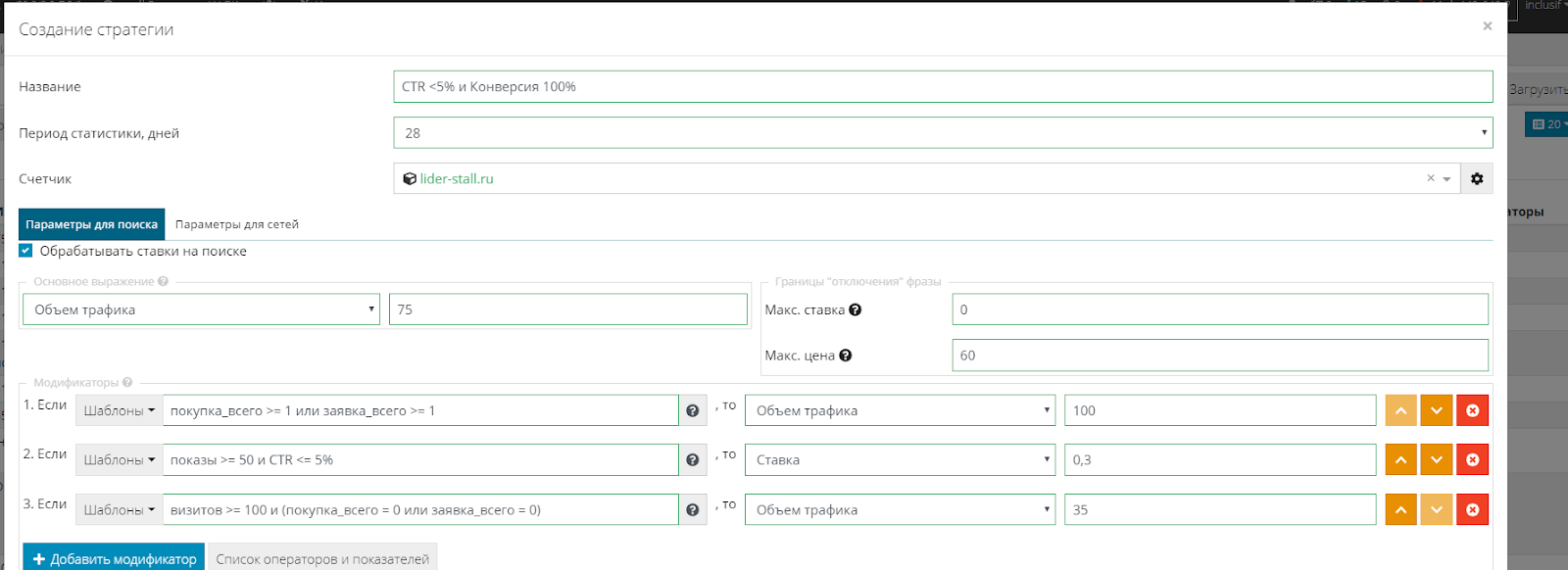
В итоге у нас получилось три модификатора со следующими настройками:
- Основное выражение: Объем трафика 75
- Макс. ставка:
- Макс. цена: 60
- Модификатор: Если: покупка_всего >= 1 или заявка_всего >= 1 , то: Объем трафика 100
- Модификатор: Если: показы >= 50 и CTR <= 5% , то: Ставка 0,3
- Модификатор: Если: визитов >= 100 и (покупка_всего = 0 или заявка_всего = 0) , то: Объем трафика 35
При этом я изменил приоритет, для того чтобы модификатор, который повышает охват для конверсионных запросов имел самый высокий приоритет:
Примеры формул для автоматизации ставок можно увидеть здесь.
Как работает массовое отключение неэффективных фраз в Яндекс.Директ
Выбираете поисковую кампанию и ключевую фразу на поиске и открываете отчет по поисковым фразам. И с этого момента начинается магия)) для активации системы просто нажмите на кнопку “Режим сбора минус-фраз”.
Специалисты, которые не один год работают с Яндекс.Директ сразу же оценят данный функционал.
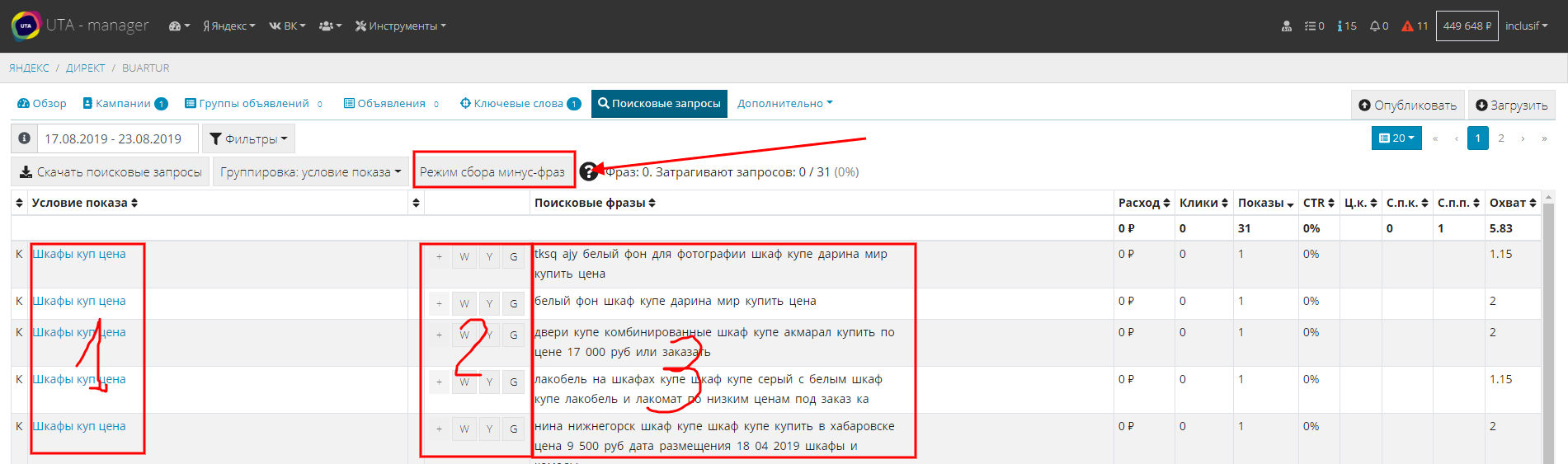
- В первом блоке мы видим условие показа. Другими словами, это ключевая фраза, которая инициировала показ.
- Второй блок нас порадует автоматизацией.
- При клике на иконку “+” поисковая фраза добавится в группу объявлений.
- При клике на иконку “W” в новой вкладке откроется Яндекс.Вордстат с выбранной поисковой фразой, для того чтобы вы могли оценить ее значимость.
- При клике на иконки “Y или G” фраза откроется в поисковой системе Яндекс или Google.
- В третьем блоке поисковая фраза, которую в действительности набирал пользователь.
Но это еще не все, самое интересное впереди. После активации режима минус-фраз система сравнивает условие показа и поисковую фразу и подсвечивает слова-добавки, что значительно упрощает обработку больших списков.
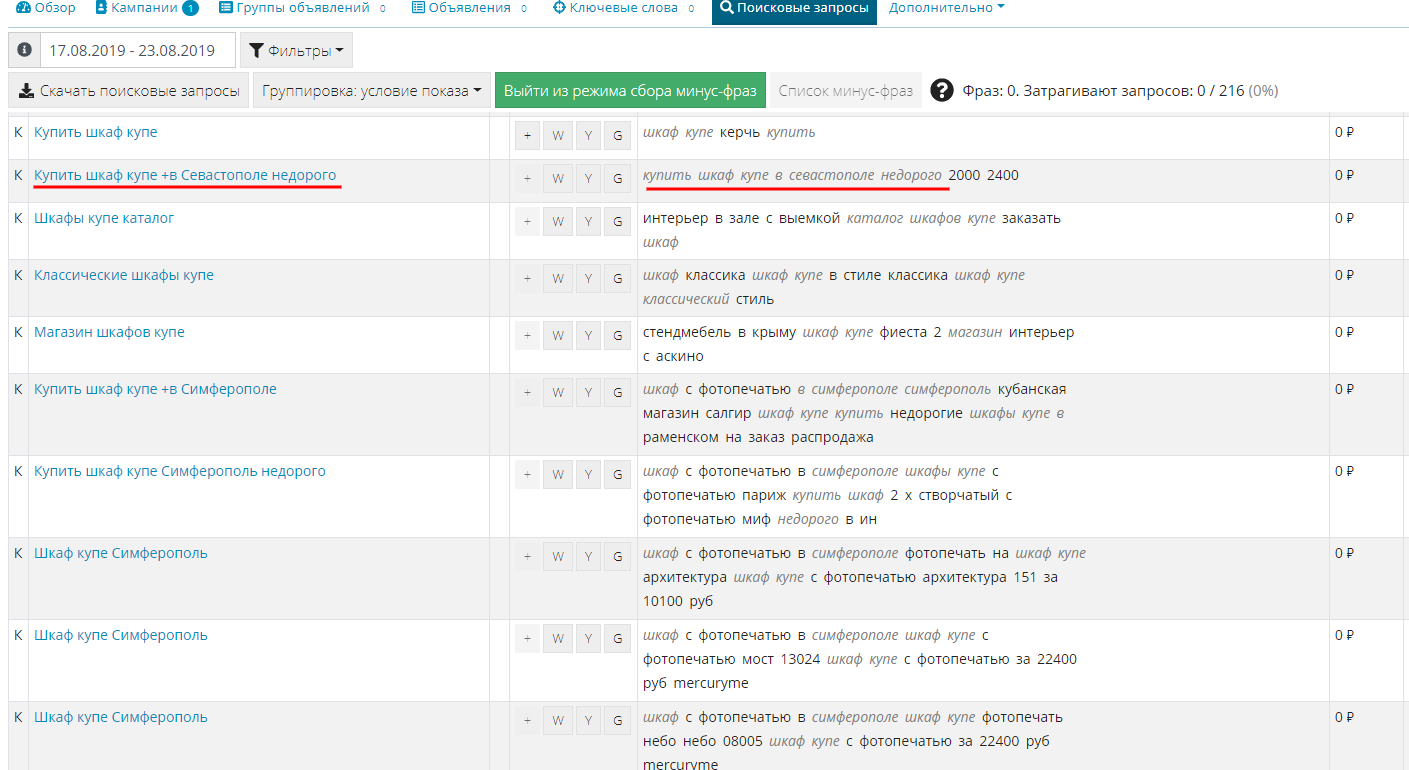
Вспоминаем проблему при сборе минус-слов “словоформы”: вот думаешь - а добавил ли я это слово или нет.
Теперь это в прошлом, система подсветит каждое добавленное слово и фразу, при этом будет учитывать словоформы.

Если вы хотите добавить минус-слово в точном соответствии (т.е. использовать оператор восклицательный знак !), зажмите Ctrl (для Mac OS “Cmd”).
При наведении на добавленное слово или фразу вы увидите, в каком формате они добавлены.
Как добавить минус-фразу?
Для этого зажмите и удерживайте клавишу Alt, после этого система переключится в режим добавления минус-фраз. Этот режим позволяет добавлять сразу несколько слов, образуя минус-фразу.
Теперь каждый клик по слову добавит его в так называемый “буфер минус-фразы”, с помощью которого вы сможете производить настройки фразы.
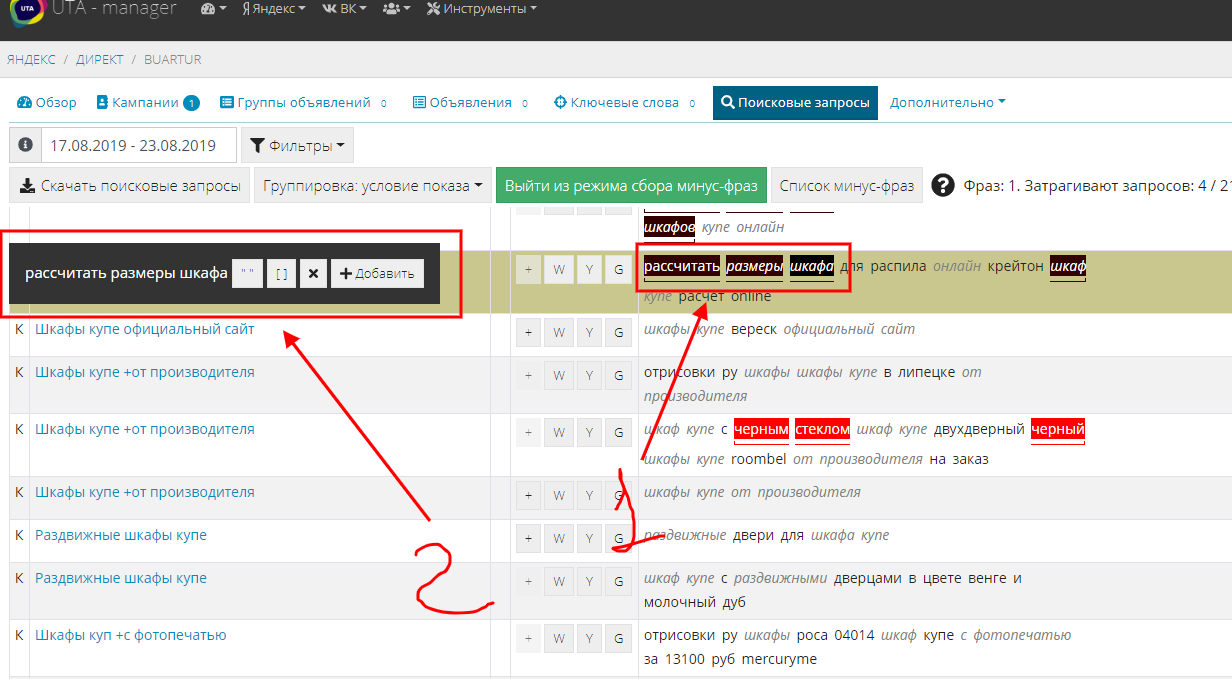
- В блоке 1 выделенная фраза.
- Во втором блоке буфер минус-фразы.
Возможности буфера минус-фраз
Если необходимо добавить одну или несколько слов во фразу в точном соответствии (с дополнительным оператором “!”), не отпуская клавиши Alt, зажмите Ctrl (для Mac OS “Cmd”) и кликните на слово.
Для более точной настройки рекомендуем применять дополнительный оператор [] (квадратные скобки). Он фиксирует порядок слов в минус-фразе, что дает возможность более тонко настраивать минусовку. Посмотрите примеры работы операторов здесь.
После настройки минус-фразы нажмите кнопку “+ Добавить”.
Как добавить собранный список минус-фраз в кампанию?
Для этого откройте собранный список минус-фраз, нажав соответствующую кнопку.
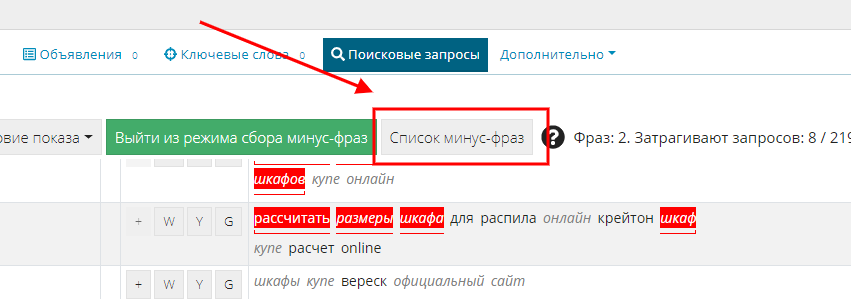
Вы можете:
- копировать список фраз;
- очищать список собранных минус-фраз (с этим осторожно)), если что - придется заново собирать фразы);
- фильтровать и удалять фразы по одной из списка.
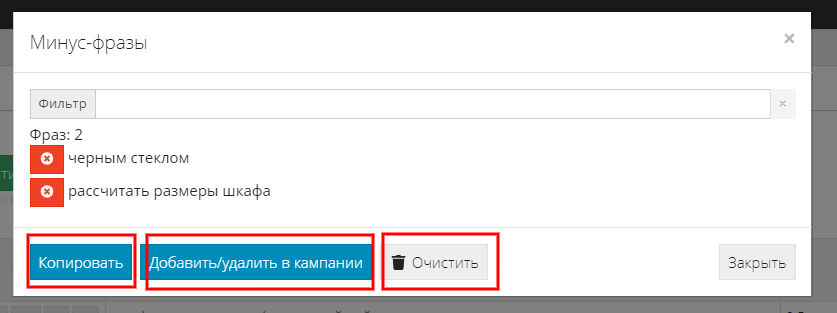
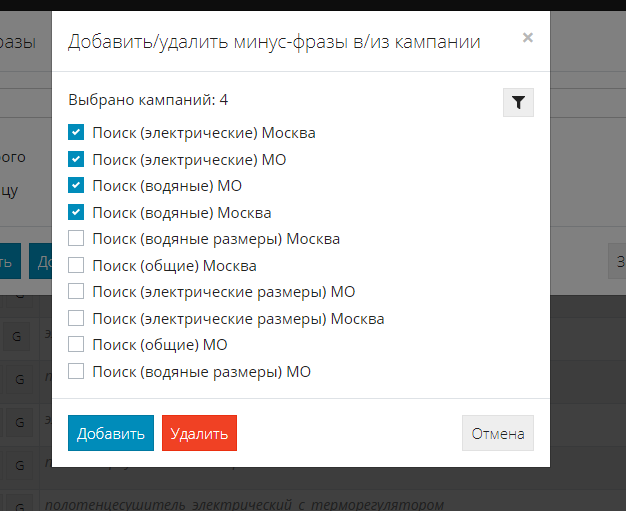
Нажмите кнопку “Добавить/удалить” в кампании - вы увидите список кампаний.
Поставьте галочки рядом с теми кампаниями, в которые вы хотите добавить/удалить собранный список минус-фраз.
После этого система запишет изменения, и их останется только отправить. Для этого перейдите на вкладку “Кампании” и в правом верхнем углу нажмите “Опубликовать”: